El material genético de todos los organismos de la naturaleza es el ácido nucleico. Hay dos tipos de ácido nucleico: DNA (abreviatura de ácido desoxirribonucleico) y RNA, que está muy relacionado con él (abreviatura de ácido ribonucleico). Algunos pequeños virus utilizan el RNA en sus genes. Todos los demás organismos y virus utilizan DNA (los virus lentos pueden ser una excepción).
Las moléculas de DNA y RNA son largas y delgadas, algunas veces extremadamente largas. El DNA es un polímero con un esqueleto regular que tiene grupos alternados de fosfato y de azúcar (el azúcar se llama desoxirribosa).
A cada grupo de azúcar está unido un grupo molecular pequeño y plano, llamado base. Hay cuatro principales tipos de bases denominados A (adenina), G (guanina), T (timina) y C (citosina). A y G son purinas; T y C son pirimidinas. El orden de las bases a lo largo de cualquier fragmento específico de DNA lleva la información genética. Hacia 1950, Erwin Chargaff descubrió que en el DNA de procedencias distintas, la cantidad de A es igual a la cantidad de T y la cantidad de G es igual a la cantidad de C. Estas regularidades se conocen como reglas de Chargaff.
El RNA tiene la misma estructura que el DNA, excepto que el azúcar es un poco diferente (ribosa en lugar de desoxirribosa) y en lugar de T tiene U (uracilo). (La timidina es en realidad 5-metiluracilo). De esta forma, el par AT se reemplaza por el par AU, que es muy similar.
El DNA se encuentra normalmente en forma de una doble hélice, teniendo dos cadenas distintas enrolladas una alrededor de otra en un eje común. Sorprendentemente, las dos cadenas corren en direcciones opuestas. Esto es, si la secuencia de átomos en el esqueleto de una cadena corre hacia arriba, entonces la otra corre hacia abajo.
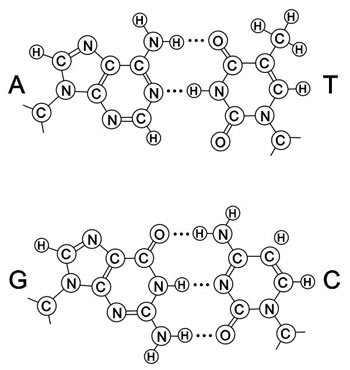
Figura A-1. Los dos pares de bases A = T y G ≡ C. Para las bases: A-adenina, T-timina, G-guanina, C-citosina. Para los átomos: C- Carbono, N-Nitrógeno, H-Hidrógeno.
A cualquier nivel, las bases están apareadas. Esto es, una base de una cadena está apareada con la base opuesta a otra de la otra cadena. Únicamente ciertos pares son posibles. Estos son:
T = A
A = T
G ≡ C
C ≡ G
Las fórmulas químicas se muestran en la figura A-l. Estos pares de bases están unidos por enlaces débiles, llamados enlaces de hidrógeno, simplificados aquí por rayas. Así, el par AT forma dos enlaces de hidrógeno y el par CG forma tres. Este apareamiento de las bases es la característica fundamental de la estructura.
Para replicar el DNA, la célula deshace las cadenas y usa cada cadena simple como un molde para guiar la formación de una nueva cadena hermana. Después de realizarse este proceso nos quedamos con dos dobles hélices, cada una conteniendo una cadena antigua y una nueva. Ya que las bases para las nuevas cadenas deben ser seleccionadas para obedecer las reglas del apareamiento (A con T, G con C), terminamos con dos dobles hélices. Cada una de ellas es idéntica en secuencia de bases a la otra y cada una con la que habíamos comenzado. En resumen, este sencillo mecanismo de apareamiento es la base molecular para que un semejante reproduzca a otro semejante. El proceso real es mucho más complicado que el que se esquematiza aquí.
Una función principal de los ácidos nucleicos es codificar para proteínas. Una molécula de proteína también es un polímero de esqueleto regular (llamado cadena polipeptídica), con los grupos laterales unidos a intervalos regulares. Tanto los esqueletos como las cadenas laterales de las proteínas son muy diferentes químicamente del esqueleto y de los grupos laterales de los ácidos nucleicos. Además, hay veinte distintos grupos laterales en las proteínas, a diferencia de los cuatro que se encuentran en los ácidos nucleicos.
En la figura A-2 se muestra la fórmula química general de una cadena polipeptídica. Las «cadenas laterales» están unidas en los puntos marcados R, R', R'' y así sucesivamente. La fórmula química exacta de cada una de las veinte diferentes cadenas laterales se conoce y puede ser encontrada en cualquier texto de bioquímica.
Cada cadena polipeptídica está formada uniendo cabeza con cola pequeñas moléculas llamadas aminoácidos. La fórmula general para un aminoácido aparece en la figura A-3, en la que R representa la cadena lateral, que es diferente para cada uno de los veinte aminoácidos mágicos. Durante este proceso se elimina una molécula de agua en cada enlace. (Los pasos químicos reales son un poco más complicados que esta simple descripción).
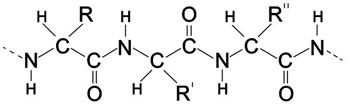
Figura A-2. Las fórmulas químicas básicas para una cadena polipeptídica (aproximadamente se muestran tres repeticiones). C-Carbono, N-Nitrógeno, O-Oxígeno, H-Hidrógeno. R, R', R'', las cadenas laterales diversas (R significa residuo).
Todos los aminoácidos que se encuentran en proteínas (excepto la glicina) son aminoácidos L, en relación con sus imágenes especulares que se llaman aminoácidos D. Esta terminología se refiere a la configuración en tres dimensiones alrededor del átomo de carbono superior de la figura A-3.
La síntesis de una proteína tiene lugar en una complicada pieza de maquinaria bioquímica llamada ribosoma, ayudada por un conjunto de pequeñas moléculas de RNA llamadas tRNA (RNA de transferencia) y un número de enzimas especiales. La información de las secuencias viene proporcionada por un tipo de molécula de RNA llamada mRNA (RNA mensajero). En muchos casos este mRNA, que es de una sola cadena, se sintetiza como una copia de un fragmento particular de DNA utilizando las reglas del apareamiento de bases. Un ribosoma viaja a lo largo de una pieza de mRNA leyendo su secuencia de bases en grupos de tres cada vez, como se explica en el apéndice B. El proceso general es DNA → mRNA → proteína, donde las flechas señalan la dirección en la cual se transfiere la información de secuencia.
Para hacer las cosas aún más complicadas, cada ribosoma se construye no sólo con un conjunto de moléculas de proteína, sino también con varias moléculas de RNA, de las cuales dos son bastante grandes. Estas moléculas de RNA no son mensajeros. Forman parte de la estructura del ribosoma.
A medida que una cadena polipeptídica se sintetiza, se va plegando sobre sí misma para formar una compleja estructura tridimensional que la proteína necesita adoptar para llevar a cabo su función específica.
Hay proteínas de muchos tamaños. Una típica podría contener unos centenares de grupos laterales. De esta forma un gen es a menudo un fragmento de DNA de únicamente unos millares de pares de bases que codifica para una única cadena polipeptídica. Otras partes del DNA se usan como secuencias de control, para ayudar a genes particulares a que se pongan en marcha y se paren.
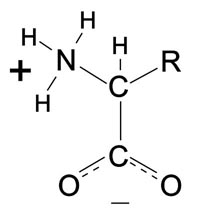
Figura A-3. Fórmula general de un aminoácido. El grupo amino es NH3+. El grupo ácido es COO–. El grupo lateral cambia de un aminoácido a otro y se simboliza por R. C-Carbono, N-Nitrógeno, O-Oxígeno, H-Hidrógeno.
Los ácidos nucleicos de pequeños virus pueden contener unos cinco mil pares de bases y codifican un puñado de proteínas. Una célula bacteriana probablemente tiene algunos millones de bases en su DNA, a menudo en una única molécula circular, y codifica varios millares de diferentes tipos de proteínas. Una de nuestras propias células contiene alrededor de tres mil millones de bases de nuestra madre y un número similar de nuestro padre, codificando algo así como 100 000 tipos de proteínas. En los años setenta se descubrió que el DNA de los organismos superiores puede contener largos fragmentos de DNA (algunos de los cuales se dan dentro de los genes y se llaman intrones) sin función aparente.
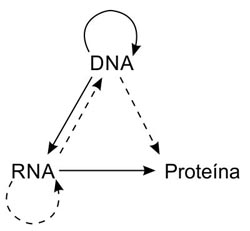
Figura A-4. Un diagrama que ilustra el Dogma Central. Las flechas representan los varios flujos de información de secuencia. Las flechas continuas muestran los flujos normales. Las flechas de puntos muestran los flujos extraños. Nótese que los flujos que faltan son las flechas que deberían empezar en las proteínas.
El llamado Dogma Central es una magnífica hipótesis que intenta predecir qué flujos de la información de secuencia no pueden darse. Estos corresponden a las flechas que faltan en la figura A-4. El flujo normal se muestra con líneas continuas, los menos frecuentes con flechas de puntos. Nótese que las flechas que faltan corresponden a todas las posibles transferencias a partir de la proteína.
Los flujos normales han sido descritos anteriormente. De los poco frecuentes, el flujo RNA → RNA se usa por parte de ciertos virus de RNA como el virus de la gripe y el de la polio. El flujo RNA → DNA (transcripción inversa) se usa por los llamados virus de RNA. Un ejemplo es el virus del SIDA. El flujo DNA → proteína no existe. Bajo condiciones especiales en el tubo de ensayo, el DNA de una sola cadena puede actuar como mensajero, pero probablemente esto nunca ocurre en la naturaleza.