
FIGURA 83.
Autorref y autorrep
EXAMINAREMOS, EN ESTE CAPÍTULO, algunos de los mecanismos originadores de autorreferencia en diversos contextos y los compararemos con los mecanismos que permiten, a algunos sistemas, autorreproducirse. Quedarán a la vista algunos notables y bellos paralelos entre ambos órdenes.
Para comenzar, veamos algunos enunciados que, a primera vista, parecen proveer los casos más simples de autorreferencia:
Todos los casos anteriores, a excepción del último (el cual es anómalo), se ajustan a un mecanismo aparentemente simple. Sin embargo, tal mecanismo dista mucho de ser simple: todos estos enunciados “flotan” en el contexto del idioma; se los puede comparar a témpanos, de los que solamente la punta está a la vista. Las secuencias de palabras constituyen esa parte visible, mientras que la invisible consiste en el procesamiento necesario para comprenderlas. En este sentido, su significación es implícita, no explícita. Ningún enunciado, por supuesto, cuenta con significación totalmente explícita, pero cuanto más explícita es la autorreferencia, más fáciles de percibir serán los mecanismos subyacentes a la misma. En el caso presente, para que pueda ser reconocida la autorreferencialidad de los enunciados, se requiere cierto grado de dominio de un idioma como el español, el cual está en condiciones de abordar la cuestión lingüística, pero también es imprescindible poder determinar el referente de la expresión “este enunciado”. Parece algo simple, pero está subordinado a nuestra capacidad —muy compleja, aunque totalmente incorporada— para valernos del español. Lo que es especialmente importante es la capacidad de determinar el referente de una frase nominal que contenga un adjetivo demostrativo. Tal aptitud es elaborada con mucha lentitud, y por ningún concepto puede ser considerada trivial. Las dificultades tal vez sean mayores cuando un enunciado como el número (4) es presentado a alguien, por ejemplo un niño, ingenuo en materia de paradojas y de artificios lingüísticos; es posible que este interlocutor diga: “¿Cuál enunciado es falso?”, y tenga que emprender un perseverante esfuerzo hasta captar la idea de que el enunciado está hablando de sí mismo; idea que, en su conjunto, afronta resistencias mentales al principio. Un par de ilustraciones puede brindar alguna ayuda (figuras 83 y 84). La figura 83 puede ser interpretada en dos niveles: en uno, es un enunciado que apunta hacia sí mismo; en el otro, es la imagen de Epiménides ejecutando su propia sentencia de muerte.
FIGURA 83.
La figura 84, que exhibe las porciones visible y no visible del témpano, sugiere la proporción relativa de enunciado que es necesario procesar para obtener el reconocimiento de la autorreferencia:

FIGURA 84.
Es entretenido intentar la creación de un enunciado autorreferencial sin utilizar el recurso de decir “este enunciado”. Se puede probar citando un enunciado dentro de sí mismo. Por ejemplo:
El enunciado: “El enunciado contiene cinco palabras” contiene cinco palabras.
Pero es un intento destinado a fracasar, pues todo enunciado que vaya a ser citado por entero dentro de sí mismo debería ser más breve que sí mismo, salvo que estemos dispuestos a tomar en consideración enunciados infinitamente extensos, tales como:
El enunciado
“El enunciado
“El enunciado
“El enunciado
.
.
.
.
.
.
.
.
etc, etc.
.
.
.
.
.
.
.
.
es infinitamente extenso”
es infinitamente extenso”
es infinitamente extenso”
es infinitamente extenso.
Pero esto no funciona en enunciados finitos. Por la misma razón, la cadena G de Gödel no puede contener el numeral explícito de su propio número Gödel: no cabría. Ninguna cadena de TNT puede contener el numeral TNT de su propio número Gödel, pues ese numeral siempre contiene más símbolos que la cadena misma. Pero existe la escapatoria de hacer que G contenga una descripción de su propio número Gödel, por medio de las nociones de “sust” y de “aritmoquinificación”.
Una manera de obtener autorreferencia en un enunciado español gracias a la descripción, en lugar del recurso de citarse a sí mismo o de utilizar la expresión “este enunciado”, es el método de Quine, ilustrado en el diálogo Aire en la cuerda de G. La comprensión de la oración de Quine requiere de un proceso mental menos sutil que los cuatro ejemplos que dimos líneas más atrás. Pese a que a primera vista parece más complicado, en realidad es, de alguna manera, un procedimiento más explícito. La construcción Quine es enteramente similar a la construcción Gödel en cuanto a la forma en que genera autorreferencia a través de la descripción de otra entidad tipográfica, la cual resulta ser isomórfica a la oración Quine misma. La descripción de la nueva entidad tipográfica es cumplida por una bipartición de la oración Quine: una de las partes es un conjunto de instrucciones para elaborar una determinada expresión, mientras que la otra contiene los materiales constructivos que han de ser empleados, o sea que es un molde. Esto se asemeja más a un pan de jabón dentro del agua que a un témpano (véase figura 85).

FIGURA 85.
La autorreferencialidad de esta oración es concretada de modo más directo que en la paradoja de Epiménides: el procesamiento recóndito que se requiere es menor. Al margen, es interesante señalar que en la oración anterior aparece la expresión “esta oración”, pero no ha sido incluida allí para ocasionar autorreferencia; el lector habrá entendido que su referente es la oración Quine, y no la oración dentro de la cual se presenta. Esto muestra precisamente que las expresiones indicativas del tipo “esta oración” son interpretadas de acuerdo al contexto que las rodee y también contribuye a probar que el procesamiento de tales expresiones es sumamente complejo.
La noción de quinereamiento y su utilización para generar autorreferencia ya fueron explicadas en el Diálogo, de modo que no hay por qué volver a ellas. En cambio, vamos a ver como la misma técnica puede ser empleada por un programa de computadora con la finalidad de reproducirse a sí mismo. El programa autorreproductor que sigue ha sido formulado en un lenguaje análogo al BuD, y su base consiste en hacer suceder a una expresión por su propia cita (esto es, el orden opuesto al del quinereamiento, por lo cual invertiré el término “quine” para obtener “eniuq”):
DEFINIR PROCEDIMIENTO "ENIUQ" [MOLDE]: IMPRIMIR [MOLDE,
PARÉNTESIS IZQUIERDO, COMILLAS, MOLDE, COMILLAS,
PARÉNTESIS DERECHO, PUNTO].
ENIUQ
['DEFINIR PROCEDIMIENTO "ENIUQ" [MOLDE]: IMPRIMIR [MOLDE,
PARÉNTESIS IZQUIERDO, COMILLAS, MOLDE, COMILLAS,
PARÉNTESIS DERECHO, PUNTO] ENIUQ'].
ENIUQ es un procedimiento definido en las tres primeras líneas y su entrada se denomina “MOLDE”. Se entiende que, cuando se apela al procedimiento, el valor de MOLDE será el de cierta cadena de caracteres tipográficos. El efecto que resulta de ENIUQ es la realización de una operación de impresión, en la cual MOLDE es impreso dos veces: la primera al desnudo, la segunda entre paréntesis y comillas simples (no dobles) y ornamentado con un punto final. Así, si el valor de MOLDE fuera la cadena REPITO PITO, la aplicación de ENIUQ produciría:
REPITO PITO ['REPITO PITO']
Ahora bien, en las cinco últimas líneas del programa anterior, se apela al procedimiento ENIUQ a través de un valor específico de MOLDE —a saber, la larga cadena encerrada por las comillas simples: DEFINIR… ENIUQ. Este valor ha sido cuidadosamente seleccionado: consiste en la definición de ENIUQ, seguida por la palabra ENIUQ. De este modo se logra que el programa mismo —o, si se quiere, una perfecta reproducción suya— resulte impreso. Es algo muy similar a la versión de Quine del enunciado de Epiménides:
“produce falsedad cuando es precedida por su cita”
produce falsedad cuando es precedida por su cita.
Es sumamente importante comprender que la cadena de caracteres que aparece entre comillas en las tres últimas líneas del programa anterior —esto es, el valor de MOLDE— no debe ser interpretado jamás como una secuencia de instrucciones. Si eso parece es, en cierto sentido, nada más que por accidente; como ya se dijo, la cadena de caracteres pudo muy bien haber sido REPITO PITO o cualquier otra. La belleza del esquema reside en que, cuando aparece la misma cadena en las tres líneas superiores del programa, es operada como un programa (porque no está entre comillas). De tal modo, en este programa una cadena funciona de dos formas: en primer lugar, como programa; en segundo lugar, como cuerpo de datos. Éste es el secreto de los programas de autorreproducción y, como veremos, de las moléculas autorreproductoras. Y ya que estamos, conviene establecer que identificaremos a todo objeto o entidad autorreproductores como autorrep, y a todo objeto o entidad autorreferenciales como autorref. En adelante haré uso ocasional de estas denominaciones.
El programa precedente es un ejemplo preciso de programa autorreproductor, formulado en un lenguaje que no estaba previsto específicamente para facilitar la formulación de autorreps. Así, la tarea fue cumplida mediante la utilización de nociones y operaciones a las que se manejó, sin que lo sean, como parte del lenguaje; la palabra COMILLAS, por ejemplo, o la orden IMPRIMIR. Supongamos, empero, que se idease un lenguaje expresamente destinado a formular autorreps con facilidad; en este caso, se podrían formular autorreps mucho más breves. Digamos, por ejemplo, que la operación de enjugar fuese un rasgo constructivo del lenguaje, que no necesita definición explícita (tal como supusimos con respecto a IMPRIMIR). Una autorrep diminuta, entonces, sería la siguiente:
ENIUQ ['ENIUQ'].
Un resultado muy similar a la versión de la Tortuga de la versión de Quine de la autorref de Epiménides, donde se da por supuesto que el verbo “quinerear” es conocido:
“produce falsedad cuando es quinereada”
produce falsedad cuando es quinereada.
Pero las autorreps pueden ser más cortas. En algunos lenguajes de computadora, por ejemplo, puede incorporarse la convención de que todo programa cuyo primer símbolo es un asterisco sea copiado antes de ser ejecutado normalmente. Luego, ¡el programa que consiste solamente en un asterisco es una autorrep! Se puede objetar su banalidad y el hecho de que dependa de una convención totalmente arbitraria, pero ello sólo confirmaría mi observación anterior en el sentido de que es casi fraudulento utilizar la expresión “este enunciado” para lograr autorreferencialidad, pues reposa excesivamente en el procesador y no lo suficiente en instrucciones explícitas para la obtención de autorreferencialidad. Emplear un asterisco como ejemplo de autorrep es como emplear la palabra “Yo” como ejemplo de autorref: en ambos casos quedan ocultos todos los aspectos interesantes de los problemas respectivos.
Esto trae a la memoria otro curioso tipo de autorreproducción: la que producen las máquinas fotocopiadoras. Se puede sostener que todo documento escrito es una autorrep, porque da lugar a que sea impresa una copia de sí mismo cuando es colocado en una máquina fotocopiadora y a ésta le es oprimido el botón correspondiente. De alguna manera, sin embargo, esto transgrede nuestra noción de autorreproducción: la hoja de papel no es consultada en absoluto y, por lo tanto, no instruye acerca de su propia reproducción. Otra vez acá, toda la tarea está en manos del procesador. Antes de que asignemos a determinada cosa la calificación de autorrep, necesitamos contar con la certidumbre de que contiene explícitamente, con la máxima extensión posible, las indicaciones necesarias para su autocopiado.
No cabe duda de que la explicitud es una cuestión de grados: aun así, existe una frontera intuitiva a uno de cuyos lados nos es dado percibir la genuina autorreproducción autodirigida, mientras que en el otro lado vemos meramente un trabajo de copia efectuado por una inflexible y autónoma máquina copiadora.
Ahora bien, en toda discusión a propósito de autorrefs y autorreps, más tarde o más temprano se plantea la cuestión esencial: ¿qué es una copia? Ya abordamos este tema, muy seriamente, en los Capítulos V y VI; volveremos ahora sobre ello. Para ir entrando en materia, describiremos algunos ejemplos sumamente caprichosos, aunque eficaces, de autorrep.
Imaginemos una cafetería donde hay una gramola que, cuando le son oprimidos los botones 5-P, pasa una canción cuya letra dice:
Pon en esta gramola
otra moneda de diez,
lo único que quiero es
un 5-P y música, música española.
Hagamos un diagrama de lo que sucede (figura 86):

FIGURA 86. Una canción autorreproductora.
A pesar de que el efecto conseguido es que la canción se reproduzca a sí misma, sonaría extraño llamar autorrep a la canción, en virtud del hecho de que, cuando atraviesa el estadio 5-P, no toda la información está allí. La información se actualiza solamente porque está enteramente almacenada en la gramola, esto es, en una de las flechas del diagrama y no en ninguno de los óvalos del mismo. Es discutible que la canción contenga una descripción completa de cómo lograr su repetición, puesto que la pareja de símbolos “5-P” es nada más que un disparador, no una copia.
Consideremos ahora un programa de computadora que se imprima a sí mismo de atrás para adelante. (Algún lector puede divertirse pensando cómo formular un programa así en el lenguaje similar a BuD mencionado hace poco, utilizando la autorrep dada como modelo). ¿Este extraño programa sería admitido como autorrep? En cierta perspectiva, sí, porque una leve transformación realizada en su salida bastará para restaurar el programa original. Parece legítimo decir que la salida contiene la misma información que el propio programa, sólo que reformulado de una manera simple. Pero no hay duda de que alguien puede examinar la salida y no reconocerla como un programa impreso hacia atrás. Apelando a la terminología acuñada en el Capítulo VI, podríamos decir que el “mensaje interior” de la salida y el del programa son el mismo, pero que éstos tienen diferentes “mensajes exteriores”: es decir, deben ser leídos mediante la utilización de mecanismos diferentes de decodificación. Ahora, si uno considera al mensaje exterior como parte de la información —lo cual da la impresión de ser absolutamente razonable— la información total, entonces, no es en definitiva la misma, por lo cual el programa no puede ser reputado autorrep.
Con todo, esta conclusión es perturbadora, porque estamos acostumbrados a aceptar que un objeto cualquiera, y su imagen reflejada por un espejo, contienen la misma información. Pero recordemos que, en el Capítulo VI, pusimos el concepto de “significación intrínseca” en dependencia con respecto a una hipotética noción universal de inteligencia. Esto quería decir que, para determinar la significación intrínseca de un objeto, podíamos pasar por alto ciertos tipos de mensaje exterior: aquellos que pueden ser universalmente comprendidos. Es decir, si el mecanismo decodificador parece brindar las bases necesarias, en algún sentido aún no bien definido, el mensaje interior que dicho mecanismo permite revelar es la única significación que importa. En este ejemplo, sería razonable conjeturar que una “inteligencia estándar” habrá de considerar que las imágenes reflejadas en dos espejos contienen ambas la misma información; en otros términos, habrá de considerar que el isomorfismo existente entre las dos imágenes es tan fútil que merece ser ignorado. De tal modo, nuestra intuición de que el programa, en alguna medida, es una legítima autorrep puede quedar en pie.
Otro ejemplo de autorrep bastante forzado sería un programa que se imprimiera a sí mismo, pero traducido a un lenguaje de computadora diferente. Esto podría ser comparado con la curiosa versión de Quine de la autorref de Epiménides:
“est une expression qui, quand elle est précédée de sa traduction, mise entre guillemets, dans la langue provenant de l’autre côté des Pyrénées, crée une fausseté” es una expresión que, cuando es precedida por su traducción, puesta entre comillas, a la lengua procedente del otro lado de los Pirineos, produce una falsedad.
El lector puede tratar de formular el enunciado descripto mediante la extraña mixtura precedente. (Sugerencia: no se trata de esta descripción misma, al menos si “misma” es considerada en forma ingenua). Si la noción de “autorrep por movimiento retrógrado” (o sea, un programa que hace la formulación de sí mismo hacia atrás) nos hace evocar un canon cangrejo, la noción de “autorrep por traducción”, a su vez, también nos hace evocar un tipo de canon: el que contiene una transposición del tema a otra tonalidad.
La idea de dar salida impresa a la traducción de un programa en lugar de hacerlo con la copia exacta del original puede que parezca insustancial. Sin embargo, si se quiere formular un programa autorrep en BuD o en BuL, es necesario echar mano de algún recurso similar porque, en esos lenguajes, SALIDA es siempre un número y no una cadena tipográfica. En consecuencia, se debería conseguir que el programa imprimiera su propio número Gödel: un gigantesco entero cuya expansión decimal codifique el programa, carácter por carácter, mediante el empleo de codones de tres dígitos. El programa se aproximará todo lo que pueda a imprimirse a sí mismo, dentro de los medios de que dispone: da salida impresa a una copia de sí mismo en otro “espacio”, y es fácil que haya deslizamientos entre el espacio de los enteros y el espacio de las cadenas. Luego, el valor de SALIDA no es un simple disparador, como “5-P”: toda la información del programa original reposa “cerca de la superficie” de la salida.
Lo anterior se asemeja mucho a la descripción del mecanismo de autorref G de Gödel. Después de todo, esa cadena de TNT contiene una descripción, no de sí misma, sino de un entero (la aritmoquinificación de u). Tanto es así que ese entero es una “imagen” exacta de la cadena G, en el espacio de los números naturales. Por ende, G se refiere a la traducción de sí misma a otro espacio. Nos sentimos cómodos llamando cadena autorreferencial a G, pese a lo que acabamos de decir, porque el isomorfismo entre los dos espacios es tan estrecho que podemos considerar idénticos a éstos.
Ese isomorfismo que refleja a TNT dentro del reino abstracto de los números naturales puede ser comparado al cuasi isomorfismo que refleja al mundo real dentro de nuestros cerebros, a través de símbolos. Los símbolos juegan papeles cuasi isomórficos con respecto a los objetos, y es gracias a ellos que podemos pensar. De igual manera, los números Gödel juegan papeles isomórficos con respecto a las cadenas, y es gracias a ellos que podemos descubrir significaciones metamatemáticas en enunciados referidos a números naturales. Lo pasmoso, casi mágico, de G, es que se las ingenia para obtener autorreferencia a pesar de que el lenguaje en el cual está formulada TNT, no parece abrir ninguna esperanza de que puede referirse a sí mismo, a diferencia de un lenguaje idiomático como el inglés o el español, dentro de los cuales el hablar acerca de sí mismos es la cosa más fácil del mundo.
Por consiguiente, G es un ejemplo destacado de autorref por vía de traducción… para nada el caso más transparente. Uno podría, asimismo, remitirse a algunos de los Diálogos que son, por su parte, autorrefs por vía de traducción: la Sonata para Aquiles solo, por ejemplo. En este Diálogo, aparecen varías referencias a las Sonatas de Bach para violín solo, y es particularmente interesante la propuesta de la Tortuga en el sentido de imaginar acompañamientos de clavicordio. En definitiva, si uno aplica esta idea al Diálogo mismo, inventa las líneas a cargo de la Tortuga; pero si uno da por supuesto que se trata solamente de la voz de Aquiles (tal cual como el violín), es un rotundo error atribuir línea alguna a la Tortuga. En cualquier caso, he aquí una autorref lograda en virtud de una correspondencia que, a su vez, surge del hecho de que los Diálogos calcan composiciones de Bach. Y esta proyección, por supuesto, se ha dejado al alcance de la advertencia del lector. Así y todo, aun cuando el lector no la advierta la proyección sigue allí, y el Diálogo sigue siendo autorref.
Acabamos de señalar semejanzas entre autorreps y cánones. Para seguir con ello, ¿dónde habría algo válidamente análogo a un canon por aumentación? Se presenta una posibilidad: tomar en consideración un programa que contenga un bucle falso, cuyo único propósito fuera el de agregarle lentitud al programa. Podría haber un parámetro que indique la frecuencia de repetición del bucle. La autorrep que se elabore daría salida impresa a una copia de sí misma, pero con el parámetro cambiado, de modo que cuando esa copia sea procesada, lo haga a la mitad de la velocidad de su programa paterno; y la “hija” de esa copia será procesada a la mitad de la mitad de la velocidad, y así siguiendo… Ninguno de estos programas se imprimirá exactamente de sí mismo; sin embargo, no hay duda de que todos pertenecen a una misma “familia”. Esto trae a la memoria la autorreproducción de los organismos vivos. Indudablemente, un individuo nunca es idéntico a ninguno de sus padres; ¿por qué, entonces, el acto de gestar nuevos seres es llamado “autorreproducción”? La respuesta es que hay un isomorfismo de grano grueso entre padres e hijos: es un isomorfismo que preserva la información relativa a la especie. Así, lo reproducido es la clase, no el caso. Es lo que sucede en la representación recursiva diseño G, del Capítulo V: la proyección entre “mariposas magnéticas” de diversos tamaños, y ciertas formas, es de grano grueso; no hay dos que sean idénticas, pero todas ellas pertenecen a la misma “especie”, y la proyección, precisamente, preserva ese hecho. En términos de programas de autorreplicación, esto integraría una familia de programas, todos ellos formulados en “dialectos” de un mismo lenguaje de computadora, donde cada uno puede formularse a sí mismo, pero de un modo ligeramente modificado, de lo cual resulta un dialecto del lenguaje original.
Quizá el ejemplo más solapado de autorrep sea el siguiente: en vez de formular una expresión legítima del lenguaje compilador, se teclea uno de los mensajes de error, propios del compilador. Cuando el compilador observa su “programa”, lo primero que hace es sentirse confundido, porque ve que su “programa” es no gramatical; entonces, da impresión de salida a un mensaje de error. Todo lo que se necesita maquinar es que este mensaje coincida con el que se tecleó al principio. Esta clase de autorrep, que me fuera sugerida por Scott Kim, saca partido de un nivel del sistema que difiere del nivel al que uno normalmente se aproximaría. Aunque parezca un ejemplo baladí, podemos encontrar equivalentes del mismo en sistemas complejos donde las autorreps compiten entre sí para sobrevivir, como lo veremos muy pronto.
Además de la pregunta “¿Qué es una copia?”, hay otra pregunta filosófica fundamental con respecto a los autorreps. Constituye la otra cara de la moneda, y dice: “¿Qué es el original?”. Lo mejor será explicarla a través de algunos ejemplos:
Está claro que, en (1), el programa es la autorrep. Pero en (3), ¿la autorrep es el programa, o el sistema combinado de programa más intérprete, o la unión de programa, intérprete y procesador?
Ciertamente, una autorrep puede involucrar algo más que la sola autoimpresión. La mayor parte de lo que sigue, en este capítulo, está dedicado a hablar de las autorreps en las cuales los datos, el intérprete y el procesador están profundamente entrelazados, y donde la autorreplicación implica la replicación de todos ellos a un mismo tiempo.
Estamos ya a punto de introducirnos en uno de los temas más fascinantes y complejos de este siglo: el estudio de “la lógica molecular del estado vivo”, para utilizar la expresión altamente sugerente de Albert Lehninger. Es una lógica, sin duda, pero de un género más bello y complejo que el imaginado por cualquier mente humana. La abordaremos desde un ángulo un tanto original: a través de un juego de artificio, de un solitario al cual he llamado Tipogenética, abreviatura de “Genética Tipográfica”. Mediante la Tipogenética, he tratado de capturar algunas ideas del ámbito de la genética molecular dentro de un sistema tipográfico que, a primera vista, se asemeja mucho a los sistemas formales ejemplificados por el sistema MIU. La Tipogenética, por supuesto, abarca gran cantidad de simplificaciones, y por tanto su utilidad principal es de índole didáctica.
Debo decir, sin demora, que el campo de la biología molecular es un sitio donde interactúan fenómenos correspondientes a diversos niveles, y que la Tipogenética intentará solamente la ilustración de fenómenos de uno o dos niveles. En particular; se han omitido los aspectos puramente químicos, pues pertenecen a un nivel ubicado por debajo del que trataremos aquí; de modo similar, también se han omitido todos los aspectos relacionados con la genética clásica (esto es, la genética no molecular), en este caso porque pertenecen a un nivel ubicado por encima del que trataremos aquí. Con la Tipogenética, únicamente pretendo aportar una visión intuitiva de los procesos centrados en torno al famoso Dogma Central de la Biología Molecular, enunciado por Francis Crick (uno de los codescubridores de la estructura en doble hélice del ADN):
ADN ⇒ ARN ⇒ proteínas.
Espero que el muy esquemático modelo que he construido permita la percepción, por parte del lector, de ciertos principios simples que unifican el campo y que presentados de otra manera pueden quedar oscurecidos por la interacción enormemente complicada de los fenómenos, en muy distintos niveles. Lo que se sacrifica es, por supuesto, la exactitud rigurosa; lo que se gana, así confío, es un poco de comprensión.
El juego de la Tipogenética comprende la manipulación tipográfica de secuencias de letras. Estas últimas son las siguientes:
A C G T
Las secuencias arbitrariamente formadas con ellas son llamadas cadenas. Así, algunas cadenas son:
GGGG
ATTACCA
GATAGATAGATA
Dicho al margen, “CADENA” contiene en sí el anagrama “ADN CAE”. Es una coincidencia adecuada porque las cadenas, en Tipogenética, llenan la función de secciones de ADN —las cuales, en la genética real, son llamadas frecuentemente “cadenas”—. No sólo ello, sino que el anagrama completo muy bien puede ser interpretado como las siglas de “ADN Correo Aéreo Expreso”; también esto es muy oportuno, pues la función de “ARN mensajero” —que en Tipogenética también es representada por cadenas— resulta magníficamente caracterizada por la expresión “Correo Aéreo Expreso”, aplicada al ADN, como veremos más adelante.
En ocasiones me referiré a las letras A, C, G, T como bases; y a las posiciones que ocupen, como unidades. Así, en la segunda de las cadenas enunciadas más arriba, hay siete unidades, en la cuarta de las cuales se encuentra la base A.
Si se tiene una cadena, es posible operar sobre ella y modificarla de diversas maneras. Se pueden producir cadenas adicionales, bien mediante el copiado, bien seccionando una cadena en dos; algunas operaciones alargan las cadenas, otras las reducen y otras más no alteran su longitud.
Las operaciones se presentan en paquetes, es decir, diversas operaciones que deben ser realizadas en conjunto, ordenadamente. Tal paquete de operaciones se parece algo a una máquina programada que se moviese de un lado a otro de la cadena, produciendo ciertos efectos sobre ella; estas máquinas móviles son llamadas “enzimas tipográficas”: enzimas, para abreviar; operan sobre las cadenas a razón de una unidad por vez y se dice que están “ligadas” a la unidad sobre la cual están operando en un momento dado.
Mostraremos cómo actúan algunas especies de enzimas sobre determinadas cadenas. La primera cosa por saber es que las enzimas gustan de comenzar ligándose a una letra específica. Así, hay cuatro clases de enzimas: las que prefieren A, las que prefieren C, etcétera. Dada la secuencia de operaciones que realiza una enzima, el lector puede determinar cuál es la letra que la misma prefiere, pero por ahora solamente presentaré dicha secuencia sin explicaciones. He aquí un espécimen de enzima, que consiste en tres operaciones:
Lo que sucede con esta enzima es que gusta de ligarse inicialmente a A. Lo que sigue es un ejemplar de cadena:
AGAA
¿Qué ocurre si nuestra enzima se liga a la A de la izquierda y comienza a actuar? El paso 1 suprime la A, así que nos queda GAA, y la enzima se liga ahora a la G. El paso 2 lleva a la enzima a su derecha, a la A, y el paso 3 agrega una T, para formar la cadena GATA. La enzima, de este modo, ha completado su misión: ha transformado AGAA en GATA.
¿Y qué ocurre si se liga a la última A de la derecha de AGAA? Suprime esa A y abandona el extremo de la cadena. Dondequiera que ocurra esto, la enzima deja de operar (éste es un principio general). Luego, la única consecuencia ocasionada es la eliminación de un símbolo.
Veamos algunos ejemplos más. Ésta es otra enzima:
Ahora bien, encontramos aquí los términos “pirimidina” y “purina”; es fácil explicarlos: A y G son llamados purinas, C y T son llamados pirimidinas. Por consiguiente, buscar una pirimidina significa sencillamente buscar la C o la T más próximas.
La otra expresión nueva es Procedimiento Copiador. Cualquier cadena puede ser “copiada” sobre otra cadena, pero de una manera caprichosa. En lugar de copiar A sobre A, se la copia sobre T, y viceversa. Y, en lugar de copiar C sobre C, se la copia sobre G, y viceversa. Adviértase que una purina se copia sobre una pirimidina, y viceversa. Esto es llamado apareamiento de bases complementarias; los complementos son:
| complemento | ||
| purinas |
A ⇔ T G ⇔ C |
pirimidinas |
Para facilitar la memorización uno puede asociar a Aquiles con la Tortuga, y al Cangrejo con sus Genes.
“Copiar” una cadena, en consecuencia, no consiste realmente en copiarla, sino en elaborar su cadena complementaria; ésta, a su vez, será inscripta en forma invertida, encima de la cadena original. Veamos esto en términos concretos; tenemos una enzima anterior, digamos, que actúa sobre la cadena siguiente (también esta enzima es de las que prefieren comenzar en A):
CAAAGAGAATCCTCTTTGAT
Son muchos los lugares por donde puede comenzar; optemos, por ejemplo, por la segunda A. La enzima se liga a ella y ejecuta el paso 1: buscar, hacia la derecha, la pirimidina más cercana. Bien, esto significa una C o una T; la que aparece primero es una T, aproximadamente en el centro de la cadena, de modo que allí vamos. Sigue el paso 2: Procedimiento Copiador; bueno, basta con que ubiquemos una A invertida encima de esa T; pero eso no es todo, porque Procedimiento Copiador sigue en vigencia hasta que interrumpido, o hasta que la enzima se agote, según lo que ocurra primero. Esto significa que a cada base atravesada por la enzima mientras opera el Procedimiento Copiador le será adjudicada una base complementaria, inscripta sobre sí. El paso 3 requiere la búsqueda de una purina, hacia la derecha de nuestra T: tiene que ser la G colocada en el antepenúltimo lugar de la cadena, de izquierda a derecha. Y, al desplazarnos a esta G, debemos “copiar”, o sea, crear una cadena complementaria. He aquí el resultado:

El último paso consiste en cortar la cadena, lo cual producirá dos tramos,

y, además, AT.
Y ya está cumplido el paquete de instrucciones. Nos hemos quedado, sin embargo, con una cadena doble. Siempre que ocurra esto, separamos una de otra las dos cadenas complementarias (principio general); de manera que, en realidad, nuestro resultado final es un conjunto de tres cadenas:
AT, CAAAGAGGA y CAAAGAGAATCCTCTTTG
Adviértase que la cadena invertida ha sido puesta sobre sus pies y por consiguiente su derecha y su izquierda han sido intercambiadas.
Ya hemos visto la mayor parte de las operaciones tipográficas que pueden ser efectuadas con las cadenas; hay otras dos que deben ser mencionadas: una interrumpe el Procedimiento Copiador; la otra desplaza la enzima desde una cadena hacia la cadena invertida ubicada sobre sí. Cuando sucede esto último, uno puede conservar la hoja de papel en posición normal, pero debe entonces intercambiar “izquierda” y “derecha” en todas las instrucciones; si no, pueden seguirse textualmente las instrucciones, pero girando 180 grados la hoja de papel, de modo que la cadena de arriba se haga normalmente legible. Si se da la orden de “desplazamiento”, pero no hay base complementaria a la que pueda ligarse la enzima, en ese instante ésta se limita a separarse de la cadena y su misión queda cumplida.
Es necesario dejar señalado que, cuando aparece una instrucción de “cortar”, ésta concierne a ambas cadenas (si hay dos); en cambio, “suprimir” se aplica solamente a la cadena sobre la cual está actuando la enzima. Si Procedimiento Copiador está abierto, la orden de insertar es para ambas cadenas: la base misma en la cadena sobre la cual está actuando la enzima, y su complemento en la otra cadena. Si Procedimiento Copiador está cerrado, la orden de insertar se aplica únicamente a una cadena, de manera que en la cadena complementaria debe insertarse un espacio en blanco.
Y, siempre que Procedimiento Copiador esté abierto, las órdenes de “moverse” y “buscar” requieren que uno elabore bases complementarias para todas las bases que la enzima va tocando en su deslizamiento. Cabe mencionar que Procedimiento Copiador siempre está cerrado cuando comienza a actuar la enzima. Si Procedimiento Copiador está cerrado y surge la orden “Cerrar Procedimiento Copiador”, no sucede nada; del mismo modo, si Procedimiento Copiador, ya está abierto y la orden que surge es “Abrir Procedimiento Copiador”, tampoco sucede nada.
Hay quince tipos de órdenes, cuya lista es la siguiente.
| cor | ——— | cortar cadena(s) |
| sup | ——— | suprimir una base de la cadena |
| des | ——— | desplazar la enzima a otra cadena |
| mvd | ——— | moverse una unidad a la derecha |
| mvi | ——— | moverse una unidad a la izquierda |
| cop | ——— | abrir Procedimiento Copiador |
| crr | ——— | cerrar Procedimiento Copiador |
| ina | ——— | insertar A, a la derecha de esta unidad |
| inc | ——— | insertar C, a la derecha de esta unidad |
| ing | ——— | insertar G, a la derecha de esta unidad |
| int | ——— | insertar T, a la derecha de esta unidad |
| pid | ——— | buscar la pirimidina más cercana hacia la derecha |
| pud | ——— | buscar la purina más cercana hacia la derecha |
| pii | ——— | buscar la pirimidina más cercana hacia la izquierda |
| pui | ——— | buscar la purina más cercana hacia la izquierda |
Cada una tiene una abreviatura de tres letras; nos referiremos a estas abreviaturas de tres letras mediante la denominación de aminoácidos. Luego, toda enzima está constituida por una secuencia de aminoácidos; formulamos a continuación una enzima arbitraria:
pud-inc-cop-mvd-mvi-des-pui-int
y una cadena arbitraria:
TAGATCCAGTCCATCGA
Veremos cómo actúa la enzima sobre la cadena. Esta enzima solamente se liga a G; comencemos, pues, por ligarla a la G del centro; luego buscamos una purina hacia la derecha (o sea, A o G). Pasamos por alto (nosotros, la enzima) TCC y recalamos en A. Insertamos una C. Tenemos ahora:

donde la flecha señala la unidad a la cual está ligada la enzima. Abrimos Procedimiento Copiador, que ubica una G invertida sobre la C. Nos movemos a la derecha, luego a la izquierda, y a continuación nos desplazamos a la otra cadena. Esto es lo que tenemos hasta aquí:

Démosle vuelta, de modo que la enzima quede fijada a la cadena de abajo:

Ahora, buscamos una purina a nuestra izquierda y encontramos A. Procedimiento Copiador está abierto, pero como las bases complementarias ya están allí, no agregamos nada. Por último, insertamos una T (en Procedimiento Copiador), y nos detenemos:

Nuestro resultado final, pues, consiste en dos cadenas.
ATG y TAGATCCAGTCCACATCGA
La cadena inicial, por supuesto, ya no existe.
Ahora bien, uno puede preguntarse de dónde provienen las enzimas y las cadenas y cómo establecer las preferencias de una determinada enzima en materia de ligamiento. Una forma de resolver esto podría ser enunciar caprichosamente cadenas y enzimas, al mismo tiempo, y observar qué sucede cuando estas enzimas actúen sobre aquellas cadenas y su prole. Esto tiene algo de acertijo MU, donde encontrábamos algunas reglas de inferencia y un axioma y simplemente había que empezar. La única diferencia reside en que en este caso, cada vez que se actúa sobre una cadena la forma original de ésta desaparece definitivamente. En el acertijo MU, operar sobre MI para obtener MIU no destruía a MI.
En Tipogenética, en cambio, lo mismo que en el campo de la genética real, el esquema es mucho más complejo. Comenzamos con una cadena arbitraria, análogamente a como lo hacemos con un axioma en un sistema formal; pero al principio no contamos con ninguna “regla de inferencia”: a saber, con ninguna enzima. Sin embargo, ¡podemos traducir cada cadena a una o más enzimas! Así, las propias cadenas dictarán las operaciones por efectuarse sobre ellas, y tales operaciones producirán, a su vez, nuevas cadenas que dictarán nuevas enzimas, etc., etc… ¡Verdaderamente, una extremada mixtura de niveles! Con fines comparativos, pensemos cuán diferente resultaría el acertijo MU si cada nuevo teorema, en él, produjese a su vez, por medio de algún código, una nueva regla de inferencia.
¿Cómo se realiza esta “traducción”? Implica un Código Tipogenético mediante el cual los pares contiguos de bases —llamados “dupletes”— representan diferentes aminoácidos dentro de una misma cadena. Existen dieciséis dupletes posibles: AA, AC, AG, AT, CA, CC, etc. Y hay quince aminoácidos. La figura 87 muestra el Código Tipogenético:

FIGURA 87. El Código Tipogenético, mediante el cual cada duplete de una cadena codifica uno o quince “aminoácidos” (o un signo de puntuación).
De acuerdo con la tabla, la traducción del duplete GC es “inc” (“insertar una C”); la de AT es “des”; y así siguiendo. Por lo tanto, queda a la vista que una cadena puede dictar una enzima de manera muy directa. Por ejemplo, la cadena
TAGATCCAGTCCACATCGA
se fragmenta en dupletes del siguiente modo:
TA GA TC CA GT CC AC AT CG A
con la A separada, al final. Su traducción a enzimas es:
pid-ina-pud-mvd-int-mvi-cor-des-cop
(Tómese nota de que la A sobrante no tiene ninguna participación).
¿De qué se tratan las letras minúsculas ‘r’, ‘i’ y ‘d’ que aparecen cerca del ángulo inferior derecho de cada cuadro? Son fundamentales para determinar las preferencias de las enzimas en materia de ligamiento, y ello en una forma peculiar. Para establecer a qué letra quiere ligarse una enzima, es necesario establecer la “estructura ternaria” de la enzima, la cual es, a su vez, determinada por la “estructura primaria” de la misma. Se entiende por estructura primaria su secuencia de aminoácidos; por estructura ternaria se entiende la forma en que prefiere “plegarse”. El detalle central es que a las enzimas no les gusta desplegarse en línea recta, como las hemos exhibido hasta ahora. Cada aminoácido interno (excepción hecha de ambos extremos) tiene la posibilidad de “ensortijarse”, la cual es regida por las letras de los ángulos: ‘i’ y ‘d’ representan, respectivamente, “izquierda” y “derecha”, y ‘r’ representa a “recto”. Tomemos nuestro anterior ejemplar de enzima y pleguémoslo para mostrar su estructura ternaria. Comenzaremos con la estructura primaria de la enzima y luego la veremos extenderse de izquierda a derecha. En cada aminoácido cuya letra angular sea ‘i’, haremos un giro a la izquierda; en los que tengan la letra ‘d’ un giro a la derecha; cuando corresponda la ‘r’, no habrá giro. La figura 88 exhibe la conformación bidimensional de nuestra enzima.

FIGURA 88. La estructura ternaria de una tipoenzima.
Adviértase el giro a la izquierda en “pud”, el giro a la derecha en “des”, etc., como también que el primer segmento (“pid ⇒ ina”) y el último segmento (“des ⇒ cop”) son perpendiculares. Ésta es la clave de las preferencias en materia de ligamientos; de hecho, la orientación relativa del primero y del último segmento de la estructura ternaria de una enzima determina la preferencia en materia de ligamiento de la enzima. Siempre podemos orientar la enzima de modo que su primer segmento apunte hacia la derecha; procediendo así, el último segmento determina la preferencia de ligamiento, como lo muestra la figura 89.
Así, en nuestro caso, tenemos una enzima que opta por la letra C. Si, al plegarse, una enzima se cruza a sí misma, ello no significa ninguna dificultad; basta con pensar que está pasando por debajo o por encima de sí misma. Adviértase que todos sus aminoácidos cumplen una función en la determinación de la estructura ternaria de la enzima.
| Primer segmento | Segundo segmento | Letra de ligamiento |
| ⇒ | ⇒ | A |
| ⇒ | ⇑ | C |
| ⇒ | ⇓ | G |
| ⇒ | ⇐ | T |
FIGURA 89. Tabla de preferencias de ligamiento por parte de las tipoenzimas.
Queda una cosa por explicar: ¿por qué está en blanco el cuadro AA del Código Tipogenético? La respuesta es que el duplete AA actúa como signo de puntuación dentro de una cadena y señala el final de la codificación de una enzima. Esto es, una cadena puede codificar dos o más enzimas si contiene uno o más dupletes AA. Por ejemplo, la cadena
CG GA TA CT AA AC CG A
codifica dos enzimas:
cop-ina-pid-crr
y
cor-cop
con AA cumpliendo el papel de dividir la cadena en dos “genes”. La definición de gene es: la porción de una cadena que codifica una enzima individual. Nótese que la mera presencia de AA dentro de una cadena no significa que la cadena codifique dos enzimas. Por ejemplo, CAAG codifica a “mvd-sup”. ¡AA comienza en una unidad de numeración par y por consiguiente no es leída como duplete!
El mecanismo que descifra las cadenas y produce las enzimas que están codificadas dentro de aquéllas se denomina ribosoma. (En Tipogenética, la función de los ribosomas la cumple quien practica el juego). Los ribosomas no son responsables en absoluto de la estructura ternaria de las enzimas, pues ésta es enteramente determinada tan pronto es creada la estructura primaria. Conviene aclarar, por otra parte, que el proceso de traducción siempre se dirige desde las cadenas a las enzimas, jamás en sentido opuesto.
Ahora que ya están expuestas todas las reglas de la Tipogenética, sería interesante comenzar a jugar. En forma particular, sería superlativamente interesante idear una cadena que se autorreplique. Veamos qué significa esto en el transcurso de las líneas siguientes: se formula una cadena individual, sobre la cual actúa un ribosoma, que produce alguna o todas las enzimas que están codificadas en la cadena; luego, estas enzimas son puestas en contacto con la cadena original, y se les permite operar sobre ella. Esto produce un conjunto de “cadenas hijas”, las cuales atraviesan los ribosomas con la finalidad de producir una segunda generación de enzimas que, a su vez, actúan sobre las cadenas hijas; y así sucesivamente. Esto puede seguir a través de una cantidad indefinida de estadios. La única esperanza consiste en que, por último, entre las cadenas que se tengan en un punto determinado, sea posible descubrir dos copias de la cadena original (una de las copias puede ser, en realidad, la cadena original).
Los procesos tipogenéticos pueden ser representados esquemáticamente a través de un diagrama (figura 90).

FIGURA 90. El “Dogma Central de la Tipogenética: un ejemplo de “Jerarquía Enredada”.
Este diagrama ilustra el Dogma Central de la Tipogenética. Muestra cómo las cadenas definen a las enzimas (a través del Código Tipogenético) y cómo, por su parte, las enzimas actúan sobre las cadenas que les han dado origen, produciendo nuevas cadenas. En consecuencia, la línea de la izquierda refleja la manera en que la información anterior circula hacia arriba, en el sentido de que una enzima es la traducción de una cadena, y contiene por ende la misma información que la cadena, sólo que en diferente forma: específicamente, en una forma activa. La línea de la derecha, en cambio, no exhibe información que circule hacia abajo; en lugar de ello, muestra de qué manera se origina nueva información: mediante las derivaciones experimentadas por los símbolos de las cadenas.
En Tipogenética, tal como una regla de inferencia en un sistema formal, una enzima deriva ciegamente los símbolos de las cadenas, sin atender para nada a la “significación” que pudiera estar albergada en dichos símbolos. Y así es como aquí se nos presenta una extraña mezcla de niveles: por un lado, las cadenas son operadas, y entonces juegan el papel de datos (como lo indica la flecha de la derecha); por otro lado, aquéllas también dictan las acciones que deben efectuarse sobre los datos, y juegan, en consecuencia, el papel de programas (como lo indica la flecha de la izquierda). El jugador de Tipogenética es quien, por supuesto, llena la función de intérprete y de procesador. La calle de doble sentido que vincula entre sí los niveles “superior” e “inferior” de la Tipogenética muestra que, en realidad, no se puede pensar que ni las enzimas ni las cadenas están unas a un nivel más alto que las otras. Por el contrario, una representación gráfica del Dogma Central del sistema MIU presenta esta apariencia:

En el sistema MIU hay una clara distinción de niveles: sencillamente, las reglas de inferencia pertenecen a un nivel más elevado que las cadenas. Lo mismo ocurre con TNT y con todos los sistemas formales.
Sin embargo, hemos visto que en TNT los niveles se mezclan, en otro sentido; en los hechos, la distinción entre lenguaje y metalenguaje se desbarata: los enunciados acerca del sistema son reflejados dentro del sistema. Resulta que si elaboramos un diagrama que ilustre las relaciones entre TNT y su metalenguaje, surgirá algo notablemente semejante al diagrama representativo del Dogma Central de la Biología Molecular. En verdad, nuestro propósito es completar detalladamente esta comparación; para cumplirlo, empero, necesitamos indicar los sitios donde la Tipogenética y la genética verdadera coinciden y los sitios donde difieren. Ciertamente, la genética real es sumamente más compleja que la Tipogenética, pero el “esquema conceptual” que el lector ha incorporado para comprender la Tipogenética le será muy útil para guiarlo en los laberintos de la genética verdadera.
Habíamos comenzado hablando de cierta relación entre “cadenas” y ADN. Estas iniciales, son la abreviatura de “ácido desoxirribonucleico”. El ADN de la mayor parte de las células reside en el núcleo de éstas, el cual consiste en una pequeña área protegida por una membrana. Gunther Stent ha calificado al núcleo como la “sala del trono” de la célula, con el ADN en función de mandatario. El ADN consiste de extensos encadenamientos de moléculas relativamente simples llamadas nucleótidos; cada nucleótido consta de tres partes: (1) un grupo fosfato; (2) un azúcar llamado “ribosa” despojado de un átomo especial de oxígeno, y (3) una base. Sólo la base distingue a los nucleótidos entre sí, por lo cual basta con especificar su base para identificar un nucleótido. Los cuatro tipos de bases que aparecen en los nucleótidos del ADN son:
| A: | adenina | purinas |
| G: | guanina | |
| C: | citosina | pirimidinas |
| T: | timina | |
(Véase también la figura 91). Es fácil memorizar las pirimidinas porque la primera vocal de “citosina”, “timina” y “pirimidina” es la ‘i’. Más adelante, cuando hablemos del ARN, aparecerá otra pirimidina —el “uracilo”— que, desdichadamente, no estropeará dicha pauta. (Nota: las letras que representan a los nucleótidos en la genética real no estarán impresas en Quadrata, como lo están en Tipogenética).
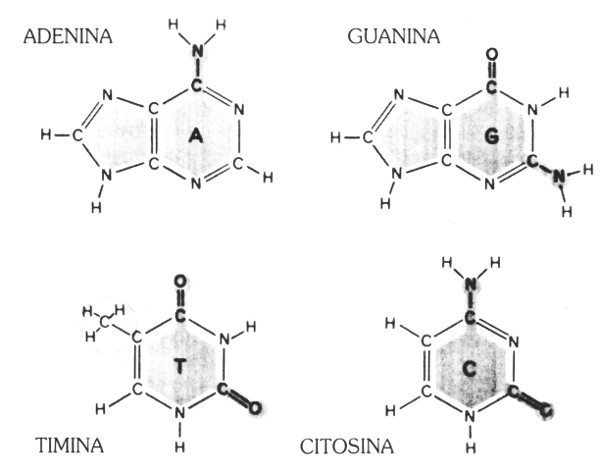
FIGURA 91. Las cuatro bases constitutivas del ADN: Adenina, Guanina, Timina, Citosina. [Tomado de Hanawalt and Haynes, The Chemical Basis of Life (San Francisco: W. H. Freeman, 1973), p. 142.]
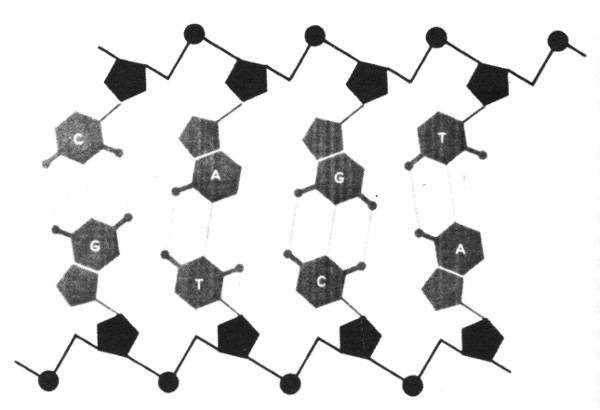
FIGURA 92. La estructura del ADN se asemeja a una escalera, cuyos lados están formados por unidades alternados de desoxirribosa y fosfato. Los peldaños están constituidos por las bases, apareadas de manera particular, A con T y G con C, reunidos por, respectivamente, dos y tres enlaces de hidrógeno. [Tomado de Hanawalt and Haynes, The Chemical Basis of Life, p. 142.]
Una cadena individual de ADN, entonces, consiste de muchos nucleótidos dispuestos como en un collar de cuentas. El enlace químico que eslabona un nucleótido con sus dos vecinos es sumamente fuerte; tales enlaces son llamados covalentes, y el “collar de cuentas” recibe a veces la denominación de espina dorsal covalente del ADN.
Ahora bien, el ADN aparece frecuentemente en cadenas dobles: es decir, dos cadenas simples que se aparean, nucleótido por nucleótido (véase figura 92). Las bases son las responsables de ese tipo peculiar de apareamiento que tiene lugar entre cadenas. Cada una de las bases de una cadena se ubica enfrente de la base complementaria de la otra cadena, y se liga a ella. Los complementos coinciden con los de la Tipogenética: A se aparea con T, y C con G; siempre una purina con una pirimidina.
En comparación con los vigorosos enlaces covalentes distribuidos a lo largo de la espina dorsal, los enlaces intercatenarios son notablemente débiles. No se trata de enlaces covalentes, sino de enlaces de hidrógeno; un enlace de hidrógeno se origina cuando dos compuestos moleculares son alineados de forma tal que un átomo de hidrógeno, inicialmente perteneciente a uno de aquéllos, “confunde” su origen, ya no sabe a cuál compuesto pertenece, pues fluctúa entre ambos, y vacila en cuanto a cuál de los dos incorporarse. A causa de que las dos mitades de la doble cadena de ADN están unidas solamente por enlaces de hidrógeno, pueden separarse o juntarse de modo relativamente fácil; y este hecho asume una gran importancia en cuanto a las funciones de la cédula.
Cuando el ADN forma dobles cadenas, éstas se entrelazan de manera tal que recuerdan la apariencia ensortijada de las vides (figura 93). Hay exactamente diez pares de nucleótidos por giro; en otras palabras, para cada nucleótido, la “enroscadura” es de 36 grados. El ADN en cadenas simples no exhibe tal forma de tirabuzón, pues ésta es una consecuencia del apareamiento de bases.
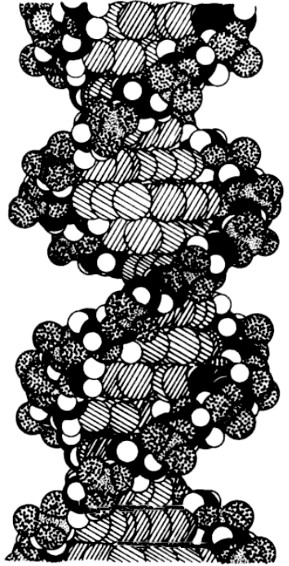
FIGURA 93. Modelo molecular de la doble hélice de ADN. [Tomado de Vernom M. Ingram, Biosynthesis (Menlo Park, Calif.: W. A. Benjamin, 1972, p. 13.]
Como ya dijimos, el ADN, soberano de la célula, habita en su “sala del trono” privada: el núcleo de la célula; así sucede en muchas de estas últimas. Pero la “vida” se mueve principalmente en el exterior del núcleo, específicamente en el citoplasma: el “fondo” de la “figura” núcleo. Las enzimas, en particular, que prácticamente hacen funcionar todo el proceso vital, son elaboradas en el citoplasma por los ribosomas, y cumplen la mayoría de sus tareas en el citoplasma. E, igual que en la Tipogenética, el diseño de todas las enzimas está almacenado dentro de las cadenas, es decir, dentro del ADN, el cual permanece protegido en el interior de su pequeño albergue nuclear. Entonces, ¿cómo hace la información relativa a la estructura de las enzimas para pasar del núcleo o los ribosomas?
Aquí es donde aparece el ARN mensajero. Más atrás, dijimos jocosamente que las cadenas de ARN mensajero —ARNm— constituían una especie de Correo Aéreo Expreso de ADN: pero esto no quiere decir que el ARNm transporte físicamente al ADN a ninguna parte, —¡ni menos por vía aérea!— sino que se encarga de trasladar la información, o mensaje, desde su sitio de almacenamiento en la cámara nuclear del ADN, hasta los ribosomas, en el citoplasma. ¿Cómo se produce esto? En una forma sencilla: una clase especial de enzima copia fielmente, dentro del núcleo y sobre una nueva cadena —una cadena de ARNm— largos tramos de secuencias de bases de ADN. A continuación, este mensajero abandona el núcleo y se interna en el citoplasma, donde hace contacto con gran cantidad de ribosomas, los cuales inician su tarea de creación de enzimas, ajustada a la información traída por el recién llegado.
El proceso por el cual el ADN es copiado, dentro del núcleo, en el ARNm, es llamado transcripción; en éste, las cadenas dobles de ADN tienen que ser separadas, transitoriamente, en dos cadenas simples, una de las cuales sirve como molde del ARNm. Al pasar, digamos que “ARN” es la abreviatura de “ácido ribonucleico”, el cual guarda una estrecha semejanza con el ADN, salvo que todos sus nucleótidos poseen ese átomo particular de oxígeno, en el grupo azúcar, del que carecen los nucleótidos de ADN; de ahí que, en su caso, se suprima el prefijo “desoxi”. Además, el ARN utiliza la base uracilo en lugar de la timina, de manera que la información de las cadenas de ARN puede ser representada por secuencias arbitrarias de las letras ‘A’, ‘C’, ‘G’, ‘U’. Ahora bien, cuando es obtenido el ARNm a partir de la transcripción del ADN, el proceso respectivo funciona a través del apareamiento usual de bases (salvo que U sustituye a T): así, un molde ADN y su ARNm asociado tendrían este aspecto:
DNA: ....... CGTAAATCAAGTCA ............ (molde)
ARNm: ....... GCAUUUAGUUCAGU ........... (“copia”)
Usualmente, el ARN no asume la forma de extensas cadenas dobles, pese a que puede hacerlo; se lo encuentra así, por lo común, en la forma helicoidal que también caracteriza al ADN pero, a diferencia de éste, se presenta en extensas cadenas curvadas un tanto caprichosamente.
Una vez que una cadena de ARNm ha salido del núcleo, se encuentra con esas extrañas criaturas subcelulares llamadas “ribosomas”, pero antes de explicar de qué manera es utilizado el ARNm por un ribosoma, quisiera hacer algunos comentarios sobre las enzimas y las proteínas. Las enzimas pertenecen a la categoría general de las biomoléculas llamadas proteínas, y la tarea de los ribosomas es elaborar todas las proteínas, no solamente las enzimas. Las proteínas que no son enzimas son un género mucho más pasivo de seres; muchas de ellas, por ejemplo, son moléculas estructurales, lo cual significa que actúan como las vigas, soportes y elementos similares en las construcciones: mantienen reunidas las distintas partes de la célula. Hay otras dos clases de proteínas pero, desde el punto de vista de nuestros propósitos, las proteínas principales son las enzimas, y de aquí en más no estableceré una distinción estricta al respecto.
Las proteínas están compuestas por secuencias de aminoácidos, de los cuales tenemos veinte variedades primarías, a cada una de las cuales asignamos una abreviatura de tres letras:
| ala | ——— | alanina |
| arg | ——— | arginina |
| asn | ——— | asparagina |
| asp | ——— | ácido aspártico |
| cis | ——— | cisteína |
| fen | ——— | fenilanina |
| gli | ——— | glicina |
| gln | ——— | glutamina |
| glu | ——— | ácido glutámico |
| his | ——— | histidina |
| ila | ——— | isoleucina |
| leu | ——— | leucina |
| lis | ——— | lisina |
| met | ——— | metionina |
| pro | ——— | prolina |
| ser | ——— | serina |
| tir | ——— | tirosina |
| tre | ——— | treonina |
| trf | ——— | tríptófano |
| val | ——— | valina |
Adviértase la leve discrepancia numérica con la Tipogenética, donde teníamos solamente quince “aminoácidos” formadores de enzimas. Un aminoácido es una pequeña molécula de la misma complejidad, aproximadamente, que un nucleótido: de aquí que las secciones constructivas de las proteínas y de los ácidos nucleicos (ADN, ARN) sean, también aproximadamente, del mismo tamaño. Sin embargo, las proteínas están integradas por secuencias mucho más breves de componentes; habitualmente, unos trescientos aminoácidos forman una proteína completa, mientras que una cadena de ADN consiste en cientos de miles o de millones de nucleótidos.
Ahora bien, cuando una cadena de ARNm, luego de su partida hacia el citoplasma, se topa con un ribosoma, tiene lugar un muy bello e intrincado proceso, llamado traducción. Podría decirse que este proceso de traducción está ubicado en el corazón mismo de la vida, y que son muchos los misterios conectados con él. No obstante, su esencia puede ser descripta en forma simple: comencemos por forjar una imagen pintoresca y luego trataremos de otorgarle mayor precisión; imaginemos que el ARNm es una larga cinta magnética y que el ribosoma es una grabadora. Cuando la cinta va pasando por el dispositivo pertinente de aquélla, es “leído” y convertido en música, o en otros sonidos. Así, las señales magnéticas son “traducidas” a notas: análogamente, cuando una “cinta” de ARNm pasa por la “cabeza magnética” de un ribosoma, las “notas” producidas son los aminoácidos, y las “composiciones musicales” a las que dan forma son las proteínas. En esto reside, en sentido amplio, la traducción, y así se muestra en la figura 96.
| U | C | A | G | ||
| U | fen | ser | tir | cis | U |
| fen | ser | tir | cis | C | |
| leu | ser | punt. | punt. | A | |
| leu | ser | punt. | trf | G | |
| C | leu | pro | his | arg | U |
| leu | pro | his | arg | C | |
| leu | pro | gln | arg | A | |
| leu | pro | gln | arg | G | |
| A | ila | tre | asn | ser | U |
| ila | tre | asn | ser | C | |
| ila | tre | lis | arg | A | |
| met | tre | lis | arg | G | |
| G | val | ala | asp | gli | U |
| val | ala | asp | gli | C | |
| val | ala | glu | gli | A | |
| val | ala | glu | gli | G | |
FIGURA 94. El Código Genético, por el cual cada triplete de una cadena de ARN mensajero codifica una de veinte aminoácidos (o un signo de puntuación).

Así y todo, ¿cómo un ribosoma puede producir una cadena de aminoácidos cuando lo que lee es una cadena de nucleótidos? Este misterio fue resuelto a fines de la década de los sesenta, gracias a los empeños de numerosas personas; en el corazón de la respuesta se encuentra el Código Genético: una correspondencia entre tripletes de nucleótidos y aminoácidos (véase figura 94). En sustancia, esto es enteramente similar al Código Tipogenético, salvo que aquí un codón está formado por tres bases (o nucleótidos) consecutivas, en tanto que en aquél basta con dos. Luego, tiene que haber 4x4x4 (o sea, 64) entradas en la tabla, en lugar de dieciséis. Un ribosoma se va encargando, en una cadena de ARN, de tres nucleótidos por vez, esto es, de un codón por vez, y en cada oportunidad en que esto sucede, agrega un nuevo aminoácido a la proteína que está elaborando en ese momento. Por consiguiente, una proteína surge aminoácido por aminoácido del ribosoma.
Un segmento habitual de ARNm, leído primero como dos tripletes (arriba), y después como tres dupletes (abajo): un buen ejemplo de hemiolia en bioquímica.
CUA GAU
Cu Ag Au
Sin embargo, cuando una proteína emerge de un ribosoma, no solamente se va haciendo más y más extensa, sino que se va plegando sobre sí misma en una forma extraordinariamente tridimensional, al modo de esos fuegos de artificio llamados “culebras”, los cuales se van haciendo más grandes al mismo tiempo que se ensortijan. Esta curiosa forma es llamada la estructura ternaria de la proteína (figura 95), mientras que la secuencia de aminoácidos, per se, es llamada la estructura primaria de la proteína. La estructura ternaria está implícita en la estructura primaria, como en la Tipogenética. No obstante, la fórmula para derivar la estructura ternaria a partir de la primaria es enormemente más compleja que en la Tipogenética. En verdad, uno de los principales problemas de la biología molecular contemporánea consiste en la determinación de reglas que permitan predecir la estructura ternaria de una proteína a partir de su estructura primaria, cuando ésta es conocida.
Otra discrepancia entre la Tipogenética y la genética real —que probablemente sea la más grave de todas— es la siguiente: mientras que en la Tipogenética cada aminoácido componente de una enzima es responsable de cierto “tramo de la acción” específico, los aminoácidos individuales, en el orden de las enzimas reales, no pueden sujetarse a una asignación de papeles tan nítida. La estructura ternaria en su conjunto es lo que determina el modo en el cual funcionará una enzima; no hay forma de poder decir: “la presencia de este aminoácido significa que han de verificarse tales y cuales operaciones”. En otras palabras, la contribución de un aminoácido individual, en la genética real, a la totalidad de las funciones de la enzima no es “independiente del contexto”. Empero, esta circunstancia no debe ser interpretada en el sentido de favorecer el argumento antirreduccionista de que “el todo [la enzima] no puede ser explicado como la suma de sus partes”. Esto carecería por entero de fundamento; lo que sí tendría fundamento es el rechazo de la aserción más simple según la cual “cada aminoácido contribuye a la suma de una manera que es independiente con respecto al resto de los aminoácidos presentes”. En otros términos, no se puede concebir que la función de una proteína sea construida a partir de las funciones libres de contexto de sus partes; en lugar de ello, es necesario considerar de qué forma interactúan dichas partes. Con todo, en principio es posible formular un programa de computadora que tenga como entrada la estructura primaria de una proteína, y determine primeramente su estructura ternaria, y en segundo lugar la función de la enzima. Esto implicaría una explicación absolutamente reduccionista de las funciones de la enzima, pero la determinación de la “suma” de las partes requeriría un algoritmo altamente complejo. La dilucidación de la función de una enzima, dada su estructura primaria, o inclusive la ternaria, es otro de los grandes problemas de la biología molecular contemporánea.
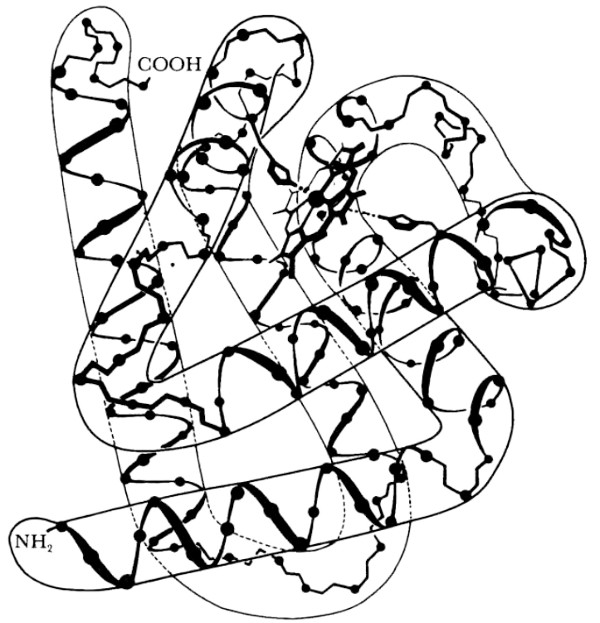
FIGURA 95. La estructura de la mioglobina, deducida de datos radiográficos de alta definición. La forma de “caño retorcido”, visible a escala mayor, es la estructura ternaria; la más menuda hélice interior —la “hélice alfa”— es la estructura secundaria. [Tomado de A. Lehninger, Biochemistry.]
En último análisis, quizá, se pueda considerar que la función de la enzima en su conjunto es construida por las funciones de las partes de una manera independiente de contexto, pero donde dichas partes son concebidas ahora como partículas individuales, al modo de los electrones y los protones, y no como “bloques”, al modo de los aminoácidos. Esto es ejemplificado por el “Dilema Reduccionista”: para explicar cualquier cosa en términos de sumas libres de contexto, es necesario descender hasta el nivel físico, pero, en tal caso, el número de partículas es tan desmesurado que aquello se convierte en nada más que un postulado teórico del género “en principio”. Luego, uno se ve obligado a establecer una suma dependiente del contexto, lo cual presenta dos desventajas; la primera es que las partes son así unidades mucho mayores, cuyo comportamiento sólo puede describirse en un nivel alto, y en consecuencia de una manera indeterminada; la segunda es que la palabra “suma” conlleva la connotación de que puede serle asignada una función simple a cada parte, y que entonces la función del todo es simplemente la suma, independiente de contexto, de esas funciones individuales. Esto, precisamente, no puede hacerse cuando se trata de explicar todas las funciones de una enzima, dados sus aminoácidos como partes. Sin embargo, para bien o para mal, se trata de un fenómeno generalizado que se plantea en la explicación de sistemas complejos. Para adquirir una comprensión intuitiva y eficaz de cómo interactúan las partes —abreviando: para poder seguir adelante— es forzoso, a menudo, renunciar a la exactitud que brinda una imagen microscópica e independiente de contexto, sencillamente a causa de que no se la puede manejar. Pero no se renuncia, en ese momento, a la convicción de que tal explicación, en principio, existe.
Volvamos, pues, a los ribosomas y al ARN y a las proteínas: dijimos que una proteína es elaborada por un ribosoma, el cual se ajusta al diseño transportado desde la “cámara real” del ADN por su mensajero, el ARN. Esto parece indicar que el ribosoma es capaz de traducir el lenguaje de los codones al de los aminoácidos, lo cual equivaldría a decir que el ribosoma “conoce” el Código Genético. Sin embargo, esa cantidad de información, lisa y llanamente, no está presente en un ribosoma. Entonces, ¿cómo se explica esto?, ¿dónde está almacenado el Código Genético? Lo llamativo es que el Código Genético está almacenado —¿dónde si no?— en el propio ADN: esto requiere algún comentario.
Conformémonos, por el momento, con una explicación parcial, en lugar de intentar un desarrollo total de este problema. Hay, flotando por todo el citoplasma, gran número de moléculas con forma de trébol de cuatro hojas; flojamente sujeto (es decir, mediante el enlace de hidrógeno) a una hoja tenemos un aminoácido, y sobre la hoja opuesta hay un triplete de nucleótidos llamado un anticodón. Para nuestros propósitos, las otras dos hojas no son pertinentes. Ésta es la forma en que tales “tréboles” son utilizados por los ribosomas en su tarea de producción de proteínas. Cuando un nuevo codón se ubica al alcance de la “cabeza magnética” del ribosoma, éste ingresa al citoplasma y toma posesión de un trébol cuyo anticodón sea complementario del codón ARN mensajero. Después, impone al trébol una posición que le permita hacerle soltar sus aminoácidos, y fijarlos covalentemente en la proteína en crecimiento. (Dicho al pasar, el enlace entre un aminoácido y su vecino, en una proteína, es un enlace covalente muy firme, denominado “enlace peptídico”. Por este motivo, las enzimas son llamadas en ocasiones “polipéptidos”). Por supuesto, no es casual que los “tréboles” transporten los aminoácidos adecuados, pues han sido elaborados según instrucciones precisas, emanadas de la “sala del trono”.

FIGURA 96. Una sección de ARNm penetrando en un ribosoma. Flotando en las proximidades hay moléculas de ARNt, llevando aminoácidos desprendidos por el ribosoma, que van a agregarse a la proteína en elaboración. El Código Genético está contenido, colectivamente, en las moléculas del ARNm. Adviértase que los apareamientos de bases (A-U, C-G) están representados en el diagrama por letras que entrelazan su trazo. [Dibujo de Scott E. Kim.]
El nombre verdadero del mencionado trébol es ARN de transferencia. Una molécula de ARNt es sumamente pequeña —aproximadamente del tamaño de una proteína minúscula— y consiste en una cadena de más o menos ochenta nucleótidos. Igual que en el caso del ARNm, las moléculas de ARNt se producen por transcripción del gran molde celular, el ADN. No obstante, las moléculas del ARNt son minúsculas, en comparación con las gigantescas del ARNm, las cuales pueden contener miles de nucleótidos dispuestos en cadenas de grandísima extensión. Además, las moléculas del ARNt se parecen a las proteínas (y difieren de las cadenas de ARNm) en este particular: tienen estructuras ternarias fijas y bien definidas, determinadas por su estructura primaria. La estructura temaría de una molécula de ARNt permite precisamente que un aminoácido se establezca en la ubicación correspondiente; seguramente, se trata de algo que es dictado, con arreglo al Código Genético, por el anticodón del brazo contrario. Una imagen vívida de la función de las moléculas del ARNt es la de una nube de palabras impresas en tarjetas, flotando en torno de un intérprete simultáneo, quien, cuando necesita traducir una palabra, lanza su mano al aire y atrapa una de aquéllas, ¡la correcta, en todos los casos! En nuestra perspectiva, el intérprete es el ribosoma, las palabras son los codones y su traducción son los aminoácidos.
Para que el mensaje interior del ADN pueda ser decodificado por los ribosomas, las tarjetas de ARNt tienen que estar diseminadas por todo el citoplasma. En cierto sentido, las moléculas del ARNt contienen la esencia del mensaje exterior del ADN, puesto que son las claves del proceso de traducción. Pero, a su vez, también provienen del ADN. De esta manera, el mensaje exterior está tratando de ser parte del mensaje interior, de una forma que nos hace recordar aquel mensaje dentro de una botella, que indicaba en qué idioma estaba escrito. Naturalmente, ningún ensayo de esta clase puede ser totalmente exitoso: no hay forma de que el ADN se alce a sí mismo mediante el uso de sus propios “ganchos”. Cierta cuota de conocimiento del Código Genético debe estar ya presente por anticipado en la célula, para permitir la elaboración de esas enzimas cuyas moléculas son obtenidas por transcripción de la copia patrón del ADN. Y este conocimiento reside en las moléculas anteriormente elaboradas de ARNt. El esfuerzo de obviar la necesidad de toda clase de mensaje exterior es semejante al del dragón de Escher, el cual procura lo más empeñosamente que puede, dentro del contexto bidimensional del mundo al que está confinado, pasar a ser tridimensional. Sus ensayos son muy meritorios, pero está descontado que jamás lo conseguirá, por más aproximadas que sean sus imitaciones de la tridimensionalidad.
¿Cómo sabe un ribosoma que una proteína ya está elaborada? Lo mismo que en Tipogenética, hay una señal que indica el momento de iniciación o de terminación de una proteína. Concretamente, hay tres codones específicos —UAA, UAG, UGA— que actúan como signos de puntuación y no como codificadores de aminoácidos. Toda vez que uno de esos tripletes encaja en la “cabeza de lectura” de un ribosoma, éste libera la proteína que estaba construyendo y comienza con otra.
Recientemente, el genoma completo del virus más pequeño que se conozca, ΦX174, ha sido puesto al descubierto. En route, surgió una revelación del todo inesperada: algunos de sus nueve genes se superponen, esto es, ¡dos proteínas distintas son codificadas por el mismo tramo de ADN! ¡Hasta hay un gen enteramente contenido en el interior de otro! Esto se pudo establecer mediante el desplazamiento, con un alcance de exactamente una unidad, de los marcos relativos de lectura de uno y otro gen. La densidad de información acumulada en un esquema semejante es increíble. Se trata, por cierto, de la lección subyacente al curioso “5/17 de haiku” del pastel de la fortuna de Aquiles, en el Canon por Aumentación interválica.
Resumiendo, surge este cuadro: desde su trono central, el ADN envía largas cadenas de ARN mensajero a los ribosomas del citoplasma; éstos, utilizando las “tarjetas” del ARNt que revolotean en torno suyo, construyen proteínas con plena eficacia, aminoácido por aminoácido, con arreglo al diseño contenido en el ARNm. Únicamente la estructura primaria de las proteínas es dictada por el ADN, pero es suficiente con ello pues, cuando emergen de los ribosomas, las proteínas se pliegan “mágicamente”, asumiendo complejas conformaciones que tienen la capacidad de actuar como poderosas máquinas químicas.
Hemos venido valiéndonos de una analogía donde los ribosomas son vistos como un magnetófono, el ARNm como una cinta grabada y las proteínas como la música generada. Puede parecer una ocurrencia arbitraria, pero hay algunos paralelos muy atrayentes. La música no es una mera secuencia lineal de notas; nuestra mente percibe la música en un nivel mucho más elevado que ése. A las notas las articulamos en frases, a las frases en melodías, a las melodías en movimientos y a los movimientos en composiciones. De manera similar, las proteínas adquieren sentido sólo cuando actúan como bloques unitarios. Aun cuando una estructura primaría transporta toda la información requerida para la creación de la estructura ternaria, no se la “siente” así porque su potencial se actualiza exclusivamente cuando la estructura temaría ha sido efectiva y físicamente creada.
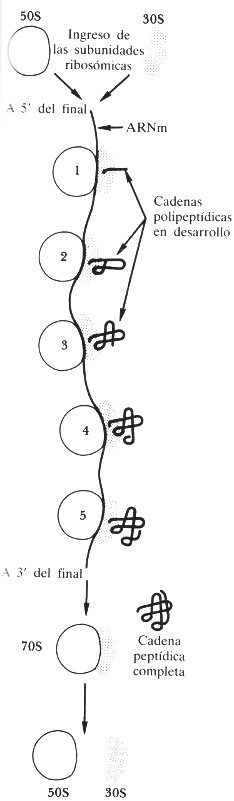
FIGURA 97. Un polirribosoma. Una cadena individual de ARNm atraviesa un ribosoma tras otro, como una cinta magnetofónica que fuera pasada por varios magnetófonos colocados en fila. El resultado es un conjunto de proteínas en desarrollo, en diversos grados de completamiento: la analogía con un canon musical es producida por el escalonamiento de los magnetófonos. [Tomado de A. Lehninger, Bioquímica.]
Conviene decir que hemos estado refiriéndonos sólo a las estructuras primaria y ternaria, de manera que alguien podría preguntarse qué se hizo de la secundaría. Por cierto, existe, lo mismo que una estructura cuaternaria. El plegamiento de una proteína tiene lugar en más de un nivel; específicamente, en ciertos puntos a lo largo de la cadena de aminoácidos, puede presentarse una tendencia a formar un tipo de hélice, llamada la hélice alfa (que no debe ser confundida con la doble hélice del ADN). Este giro helicoidal de una proteína se registra en un nivel más bajo que el de su estructura ternaria; tal nivel de estructura es visible en la figura 95. La estructura cuaternaria puede ser comparada directamente con una obra musical compuesta de movimientos independientes, a causa de que aquélla involucra el montaje de diversos polipéptidos, ya en pleno gozo de su florecimiento ternario, en una estructura mayor. Estas cadenas independientes, por lo general, están unidas por enlaces de hidrógeno y no por enlaces covalentes: lo mismo ocurre con el tipo de obra musical mencionado, donde el enlace entre movimientos es mucho menos vigoroso que el imperante en el interior de éstos, lo cual no impide, sin embargo, que el todo sea vigorosamente “orgánico”.
Los cuatro niveles de estructura: primario, secundario, ternario y cuaternario, también pueden ser comparados con los cuatro niveles de la ilustración MU (figura 60), del Preludio y Furmiga. La estructura global —consistente en las letras ‘M’ y ‘U’— es la estructura cuaternaria de la ilustración; además, cada una de esas dos partes tiene una estructura ternaria, consistente en “HOLISMO” y “REDUCCIONISMO”; la palabra en oposición, por su parte, constituye el nivel secundario, y, en la base, tenemos la estructura primaria: otra vez la palabra “MU”, repetida incontables veces.
Vamos a pasar ahora otro encantador paralelo entre las grabadoras que traducen cintas a música y los ribosomas que traducen el ARNm a proteínas. Imaginemos una gran cantidad de grabadoras, dispuestas en fila y espaciadas uniformemente. Podemos llamar “poligrabadora” a este dispositivo. Supongamos ahora una cinta que pase consecutivamente por las cabezas magnéticas de todas las grabadoras de la colección. Si la cinta contiene únicamente una extensa melodía, el resultado será un canon a muchas voces, por supuesto con la demora determinada por el tiempo que le tome a la cinta pasar de una grabadora a la siguiente. Ciertamente, en las células existen tales “cánones moleculares” allí donde numerosos ribosomas, espaciados a lo largo de líneas extensas —formando lo que se llama un polirribosoma—, “tocan”, todos ellos, la misma cadena de ARNm, produciendo como resultado proteínas idénticas, escalonadas en el tiempo (véase figura 97).
No sólo ello, sino que la naturaleza va aún más adelante. Recordemos que el ARNm proviene de la transcripción del ADN; las enzimas que son responsables de este proceso son llamadas polimerasas ARN (“-asa” es un sufijo genérico aplicado a las enzimas). Sucede a menudo que una serie de polimerasas ARN esté actuando en paralelo sobre una cadena individual de ADN, con el resultado de que se produzcan muchas cadenas separadas (pero idénticas) de ARN, distanciadas en el tiempo según el lapso que le lleve al ADN desplazarse desde una polimerasa ARN a la siguiente. Al mismo tiempo, puede haber varios ribosomas diferentes actuando sobre cada uno de los ARNm paralelos que surgen. Así es como se llega a un “canon molecular” de dos pisos, o en doble hilera (figura 98). La imagen correspondiente, en el ámbito de la música, en una situación fantástica pero graciosa: simultáneamente, diversos copistas trabajan sobre el mismo manuscrito original, el cual está en una clave que no puede ser descifrada por flautistas; la copia debe pasarlo a una clave que lo haga legible a éstos. A medida que cada uno de los copistas completa una página del original, se la entrega al copista siguiente, y comienza a transcribir otra página. Cada copista repite el mismo trabajo. Entretanto, un conjunto de flautistas va leyendo y ejecutando la melodía de cada una de las partituras que van saliendo de manos de los copistas: cada flautista, a la vez, lleva una demora en su ejecución con respecto a sus colegas que están leyendo la misma hoja.
Esta imagen un poco extravagante brinda, quizá, cierta idea acerca de la complejidad de los procesos que se cumplen en todas y cada una de las células de nuestro cuerpo durante todos los instantes de todos los días…
Hemos estado hablando de estos maravillosos organismos llamados ribosomas; ahora bien, ¿de qué están compuestos?, ¿cómo están hechos? Los ribosomas están formados por dos tipos de cosas: (1) diversas clases de proteínas, y (2) otra clase de ARN, llamado ARN ribosómico (ARNr). Así, para que se produzca un ribosoma deben estar presentes determinadas clases de proteínas, y también debe estar presente el ARNr. Naturalmente, para que estén presentes las proteínas, tienen que estar allí los ribosomas que las elaboren. ¿Cómo nos evadimos de este círculo vicioso? ¿Qué fue primero: el ribosoma o la proteína? ¿Cuál elabora a cuál? Por supuesto, no hay respuesta a estos interrogantes porque uno siempre efectúa un rastreo que lo lleva a los miembros anteriores de la misma clase —como en el caso del dilema relativo a la precedencia del huevo o de la gallina— y, por último, todo se desvanece en el horizonte del tiempo. De todas maneras, los ribosomas están hechos de dos componentes, uno grande y otro pequeño, cada uno de los cuales contiene algo de ARNr y ciertas proteínas. El tamaño de los ribosomas es, aproximadamente, el mismo que el de las proteínas grandes, y son mucho más pequeños que las cadenas de ARNm de las cuales se sirven como entrada, y a lo largo de las cuales transitan.

FIGURA 98. He aquí un esquema todavía más complejo. No sólo una sino varias cadenas de ARNm, todas surgidas por transcripción de una cadena individual de ARN, reciben la acción de los polirribosomas. El resultado es un canon molecular de dos pisos. [Tomado de Hanawalt y Haynes, The Chemical Basis of Life, p. 271.]
Algo hemos dicho de la estructura de las proteínas —de las enzimas, específicamente— pero en realidad no hemos hecho alusión a las tareas que realizan en la célula, ni al modo en que lo hacen. Todas las enzimas son catalizadoras, lo cual significa que, en cierto sentido, lo que hacen no va más allá de acelerar selectivamente distintos procesos químicos de la célula, en lugar de provocar la ocurrencia de hechos que sin su intervención no habrían tenido lugar. Una enzima actualiza determinados recorridos de entre una cantidad de miríadas de miríadas de potencialidades; por consiguiente, para establecer qué enzimas se harán presentes, es necesario establecer qué ocurrirá y qué no ocurrirá, pese a la circunstancia de que, teóricamente hablando, no es nula la probabilidad de que un proceso celular suceda espontáneamente, sin la ayuda de catalizadores.
¿Y cómo actúan las enzimas sobre las moléculas de la célula? Como ya se ha dicho, las enzimas son cadenas polipeptídicas plegadas; en todas ellas hay una ranura o cavidad, u otro rasgo superficial claramente definido, que es por donde la enzima se vincula con ciertos otros géneros de moléculas. Este punto es calificado como activo, y las moléculas con las que se combina por intermediación del mismo son llamadas sustratos; las enzimas pueden tener más de un sitio activo, y más de un sustrato. Igual que en Tipogenética, las enzimas son, por cierto, muy selectivas con respecto a su futuro campo de operaciones. El sitio activo, por lo general, es enteramente específico, y permite la combinación sólo con un determinado género de moléculas, pese a la existencia de algunos “señuelos”: otros tipos de moléculas, que pueden amoldarse al sitio activo y obturarlo, engañando a la enzima y volviéndola inactiva.
Una vez reunidos una enzima y su sustrato, hay cierto desequilibrio en cuanto a la carga eléctrica y ésta, a continuación, bajo la forma de electrones y protones, fluye en torno a las moléculas enlazadas y las reajusta. En el momento en que es alcanzado el equilibrio, pueden haber ocurrido ya algunos profundos cambios químicos en el sustrato; ejemplos de ello son los siguientes: puede haber tenido lugar una “soldadura”, a través de la cual una pequeña molécula estándar quedó unida a un nucleótido, a un aminoácido, o a otra molécula celular común; una cadena de ADN puede haber recibido un “tajo” en alguna parte de su extensión; puede haber sido cercenada una sección de una molécula; y así siguiendo. En realidad, las bioenzimas operan sobre las moléculas de una manera completamente similar al modo en que operan tipográficamente las tipoenzimas. Sin embargo, la mayor parte de las enzimas efectúan esencialmente una sola tarea, y no una secuencia de tareas. Otra diferencia saliente entre las tipoenzimas y las bioenzimas es ésta: mientras que las tipoenzimas operan únicamente sobre cadenas, las bioenzimas pueden hacerlo sobre el ADN, el ARN, otras proteínas, los ribosomas, sobre membranas celulares y, en fin, sobre lo que fuere que pertenezca a la célula. En otras palabras, las enzimas son los mecanismos universales para lograr que se hagan cosas en la célula. Hay enzimas que reúnen elementos y los fragmentan y los modifican y los activan y los desactivan y los copian y los restauran y los destruyen…
Algunos de los procesos celulares más complejos implican “cascadas”, donde una molécula individual de cierto tipo desencadena la producción de una determinada clase de enzima; comienza el proceso de fabricación, y las enzimas que salen de la “línea de montaje” abren un nuevo recorrido químico que hace posible la producción de una segunda clase de enzima. Este género de fenómeno puede ampliarse a tres o cuatro niveles, donde cada clase de enzima recién producida desencadena la producción de otra clase. Por último, surge una “lluvia” de copias de la última clase de enzima elaborada, y todas ellas se apartan y realizan su tarea específica, la cual puede consistir en cortar algún ADN “extraño”, o en colaborar con algún aminoácido del cual esté muy “sedienta” la célula, o lo que sea.
Describiremos la solución que cabe al enigma planteado por la Tipogenética: “¿Qué clase de cadena de ADN puede dirigir su propia replicación?”. Ciertamente, no toda cadena de ADN es, intrínsecamente, una autorrep. La cuestión clave es ésta: toda cadena que quiera dirigir su propia copia debe contener instrucciones para el montaje de, precisamente, las enzimas que pueden desempeñar la tarea. Ahora bien, es inútil esperar que una cadena aislada de ADN pueda ser una autorrep porque, para que esas proteínas potenciales puedan ser extraídas del ADN, tiene que haber no solamente ribosomas, sino también polimerasas ARN, las cuales hacen que el ARNm sea transportado hasta los ribosomas. Y entonces comenzamos a dar por supuesta una clase de “sistema mínimamente básico” que sea, precisamente, lo bastante sólido como para permitir que se verifiquen la transcripción y la traducción. Este sistema mínimamente básico consistirá, de este modo, en (1) determinadas proteínas, tales como polimerasas ARN, que hagan posible la elaboración de ARNm a partir del ADN, y (2) determinados ribosomas.
No es de ninguna manera casual que las expresiones “sistema básico suficientemente sólido” y “sistema formal suficientemente poderoso” suenen parecidas. Uno es el requisito necesario para que surja una autorrep, el otro para que lo haga una autorref. En realidad, esencialmente se trata de un mismo fenómeno bajo dos apariencias diferentes, a las que diseñaremos de modo explícito dentro de un momento. Pero antes, completemos la descripción de cómo una cadena de ADN puede constituir una autorrep.
El ADN debe contener la codificación para que un conjunto de proteínas lo copie. Pero hay una manera muy eficaz y precisa de copiar un tramo en doble cadena de ADN, cuyas dos cadenas sean complementarias; abarca dos pasos:
Este proceso creará dos nuevas cadenas dobles de ADN, cada una de ellas idéntica a una de las dos originales. Ahora bien, si nuestra solución tiene que basarse en esta idea, debe incluir un conjunto de proteínas, codificadas en el ADN, las que se encargarán de cumplir los dos pasos mencionados.
Se cree que, en la célula, estos pasos son realizados conjuntamente, de una forma coordinada, y que requieren la intervención de tres enzimas principales: la endonucleasa ADN, la polimerasa ADN y la ligasa ADN. La primera es una enzima “desengrapadora”: despega las dos cadenas originales y las deja a escasa distancia una de otra; luego, se detiene, y es cuando las dos enzimas restantes entran en escena. La polimerasas ADN es, básicamente, una enzima copia y mueve: traquetea las cortas cadenas simples de ADN y, complementariamente, las copia de una forma que recuerda el Procedimiento Copiador de la Tipogenética. Para efectuar la copia, extrae la materia prima —nucleótidos, específicamente— que está flotando en todo el citoplasma. Como la acción avanza por medio de arranques súbitos, un poco de desbrochamiento y un poco de copiado por vez, se producen algunas pequeñas brechas, que la ligasa ADN se encarga de taponar. El proceso es repetido una y otra vez. Esta máquina trienzimática de precisión sigue cuidadosamente adelante, a lo largo de la extensión íntegra de la molécula de ADN, hasta que el despegamiento y, simultáneamente, la replicación, son acabados, de modo que allí tendremos entonces dos copias de aquélla.
Adviértase que en la acción enzimática sobre las cadenas de ADN, el hecho de que la información esté almacenada en el ADN es casi del todo irrelevante; las enzimas, sencillamente, desempeñan sus funciones derivadoras de símbolos, tales como las reglas de inferencia en el sistema MIU. No es de interés alguno, para las tres enzimas, la circunstancia de que en determinado momento estén copiando exactamente los mismos genes que las codifican a ellas; el ADN, para éstas, es nada más que un molde sin significación ni interés.
Es sumamente atractivo comparar esto con el método que siguen las oraciones de Quine para describir cómo ha de construirse una copia de ellas mismas. Allí también se tiene una suerte de “doble cadena”: dos copias de la misma información, una que funciona como instructivo, y la otra como molde. Con respecto al ADN, el proceso es vagamente análogo, puesto que las tres enzimas (endonucleasa ADN, polimerasa ADN, ligasa ADN) están codificadas sólo en una de las dos cadenas, la cual, por consiguiente, actúa como programa, mientras que la otra cadena es meramente un molde. El paralelo no es perfecto, pues cuando se está elaborando la copia, las dos cadenas actúan como molde, y no exclusivamente una de ellas. Sin embargo, la analogía es sobremanera sugestiva.
Hay una analogía bioquímica de la dicotomía uso-mención: cuando el ADN es manejado como una simple secuencia de entidades químicas que deben ser copiadas, ello se asemeja a la mención de símbolos tipográficos; cuando el ADN dicta las operaciones que han de ser cumplidas, la semejanza es con el uso de los símbolos tipográficos.
Varios son los niveles de significación que pueden ser leídos en una cadena de ADN, según la dimensión de los bloques sobre los cuales fijamos nuestra observación, y el poder de que esté dotado el operador que se utilice. En el nivel más bajo, cada cadena de ADN codifica una cadena ARN equivalente: el proceso de decodificación se llama aquí transcripción. Si uno articula al ADN en tripletes, y luego utiliza un “decodificador genético”, puede leer al ADN como una secuencia de aminoácidos. Aquí tenemos traducción (por encima de la transcripción). En el siguiente nivel natural de la jerarquía, el ADN puede ser leído como código de un conjunto de proteínas. La extracción física de proteínas desde los genes es conocida como la expresividad del gene; por lo común, éste es el nivel más alto de nuestra comprensión de lo que quiere decir el ADN.
No obstante, con seguridad tiene que haber niveles de significación del ADN más altos aún, difíciles de discernir. Por ejemplo, es totalmente fundado pensar que el ADN de, digamos, un ser humano, codifica rasgos tales como la forma de la nariz, el talento musical, la rapidez de los reflejos, etc. ¿Nos sería posible, en principio, aprender a leer tales piezas de información, directamente, en una cadena de ADN, sin necesidad de pasar por el proceso físico de la epigénesis, es decir, la extracción física del fenotipo desde el genotipo? Presumiblemente, sí, puesto que —en teoría— se podría contar con un programa de computadora increíblemente poderoso que simule la totalidad del proceso, incluyendo cada célula, cada proteína, cada uno de los minúsculos rasgos abarcados por la replicación del ADN y de las células, exhaustivamente, hasta el último detalle. La salida de tal programa seudoepigenético sería una descripción de alto nivel del fenotipo.
Existe otra (extremadamente débil) posibilidad: la de que pudiéramos aprender a leer el fenotipo en el genotipo, sin necesidad de simular isomórficamente el proceso físico de la epigénesis, sino por la aplicación de algún género más simple del mecanismo decodificador. Esto podría ser llamado “atajo seudoepigenético”. Con atajos o sin ellos, lo cierto es que la seudoepigénesis está completamente fuera de alcance en la actualidad, con una notable excepción: en la especie Felis catus, está comprobado a través de profundas indagaciones que es posible, por cierto, leer el fenotipo directamente en el genotipo. El lector apreciará con mayor claridad, tal vez, este singular fenómeno, luego de examinar directamente la sección típica de ADN de Felis catus que se incluye a continuación:
…GATAGATAGATAGATAGATAGATAGATA…
Más abajo aparece un resumen de los niveles de lectura del ADN, junto con los nombres de los diferentes niveles de decodificación. El ADN puede ser leído como una secuencia de:
| (1) | bases (nucleótidos) | transcripción |
| (2) | aminoácidos | traducción |
| (3) | proteínas (estructura primaria) | expresividad del gen |
| (4) | proteínas (estructura ternaria) | |
| (5) | enjambres de proteínas | niveles más altos de expresividad del gen |
| (6) | ??? | niveles desconocidos de significación del ADN |
| . | ||
| . | ||
| . | ||
| (N−1) | ??? | |
| (N) | rasgos físicos, mentales y psicológicos | seudoepigénesis |
Completados estos antecedentes, estamos en condiciones ya de esbozar una elaborada comparación entre el “Dogma Central de la Biología Molecular”, sobre el cual están basados todos los procesos celulares, y que fuera formulado por F. Crick (INNEGABLE DOGMA I), y aquel al cual he denominado, con licencia poética, el “Dogma Central de la Lógica Matemática” (INNEGABLE DOGMA II), sobre el cual está basado el Teorema de Gödel. Las correspondencias entre ambos exhibidas en la figura 99 y en el diagrama que las sigue: la reunión de ambos constituye el Correspondogma Central.
| INNEGABLE DOGMA I | INNEGABLE DOGMA II | |
| (Biología Molecular) | ⇔ | (Lógica Matemática) |
| cadenas de ADN | ⇔ | cadenas de TNT |
| cadenas de ARNm | ⇔ | enunciados de N |
| proteínas | ⇔ | enunciados de metaTNT |
| proteínas que actúan sobre proteínas | ⇔ | enunciados acerca de enunciados de metaTNT |
| proteínas que actúan sobre proteínas que actúan sobre proteínas | ⇔ | enunciados acerca de enunciados acerca de enunciados de metaTNT |
| transcripción (ADN ⇒ ARN) |
⇔ | interpretación (TNT ⇒ N) |
| traducción (ARN ⇒ proteínas) |
⇔ | arimetización (N ⇒ metaTNT) |
| Crick | ⇔ | Gödel |
| Código Genético (convención arbitraria) |
⇔ | Código Gödel (convención arbitraria) |
| codón (triplete de bases) | ⇔ | codón (triplete de dígitos) |
| aminoácido | ⇔ | símbolo entrecomillado de TNT usado en metaTNT |
| autorreproducción | ⇔ | autorreferencia |
| sistema celular básico lo suficientemente sólido como para permitir la autorrep | ⇔ | sistema formal aritmético lo suficientemente poderoso como para permitir la autorref |

FIGURA 99. El Correspondogma Central. Se ha establecido una analogía entre dos Jerarquías Enredadas fundamentales: la de la biología molecular y la de la lógica matemática.
Adviértase el apareamiento de bases de A y T (Aritmetización y Traducción), y también el de G y C (Gödel y Crick). A la lógica matemática le toca el lado de las purinas y a la biología molecular el de las pirimidinas.
Para completar la faceta estética de estas correspondencias, he optado por modelar en forma absolutamente rigurosa mi esquema de numeración Gödel del Código Genético. En verdad, bajo la correspondencia que sigue la tabla del Código Genético se convierte en la tabla del Código Gödel:
| (impar) | 1 | ⇔ | A | (purina) |
| (par) | 2 | ⇔ | C | (primidina) |
| (impar) | 3 | ⇔ | G | (purina) |
| (par) | 6 | ⇔ | U | (pirimidina) |
Cada aminoácido —de los cuales hay veinte— se corresponde exactamente con un símbolo de TNT: de los cuales hay veinte. Así, por último, surgen las razones que tuve para pergeñar el “TNT austero” de manera tal que sus símbolos fuesen exactamente veinte… El Código Gödel aparece en la figura 100. Compáreselo con el Código Genético (figura 94).
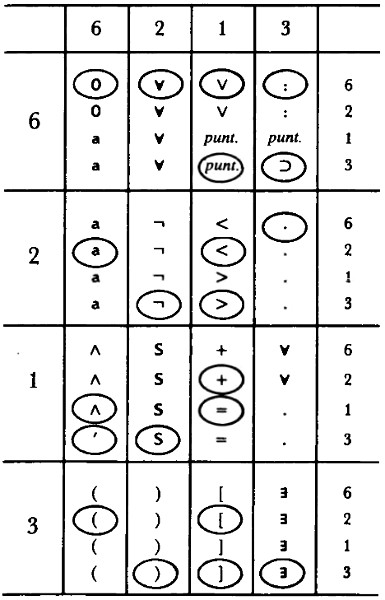
FIGURA 100. El Código Gödel. Bajo ese esquema de numeración Gödel, a cada símbolo de TNT tocan uno o más codones. Los óvalos muestran el modo en que esta tabla subsume la anterior tabla de numeración Gödel, incluida en el Capítulo IX.
Hay algo casi místico en la observación de cuán profundamente es compartida una estructura abstracta semejante por esas dos misteriosas, aunque fundamentales, conquistas del conocimiento logradas en nuestro siglo. El Correspondogmas Central no es en absoluto una demostración rigurosa de identidad entre ambas teorías, pero sí señala con claridad la profunda relación que las acerca, digna de indagaciones más amplias.
Una de las similitudes más interesantes entre los dos lados de la correspondencia es la forma en que surgen “bucles” de complejidad arbitraria en el nivel superior de ambos: a la izquierda, proteínas que actúan sobre proteínas que actúan sobre proteínas y así siguiendo, hasta el infinito; a la derecha, enunciados acerca de enunciados acerca de enunciados de meta TNT, y así hasta el infinito. Son como las heterarquías de que hablamos en el Capítulo V, en las cuales un sustrato lo suficientemente complejo permite que aparezcan Bucles Extraños de alto nivel, recíproca y cíclicamente imbricados, y tabicados por completo con respecto a los niveles más bajos. Exploraremos esta noción de una manera más detallada en el Capítulo XX.
De paso, es posible que el lector se plantee esta pregunta: “¿dónde está la contraparte del Teorema de la Incompletitud de Gödel, siguiendo el Correspondogma?”. Es un tema excelente para ser considerado antes de avanzar en la lectura.
Resulta que el Correspondogma Central es perfectamente similar a la proyección tendida, en el Capítulo IV, entre el Contracrostipunctus y el Teorema de Gödel. En consecuencia, pueden establecerse paralelos entre los tres sistemas:
En el listado que sigue se explica esmeradamente la correspondencia entre los sistemas 2 y 3.
| Contracrostipunctus | Biología Molecular | |
| fonógrafo | ⇔ | célula |
| fonógrafo “perfecto” | ⇔ | célula “perfecta” |
| disco | ⇔ | cadena de ADN |
| disco ejecutable por un fonógrafo dado | ⇔ | cadena de ADN reproducible por una célula dada |
| disco inejecutable por ese fonógrafo | ⇔ | cadena de ADN irreproducible por una célula dada |
| proceso de convertir surcos de discos en sonidos | ⇔ | proceso de transcripción del ADN en el ARNm |
| sonidos producidos por el fonógrafo | ⇔ | cadenas de ARN mensajero |
| traducción de los sonidos a vibraciones del fonógrafo | ⇔ | traducción del ARNm a proteínas |
| correspondencia entre sonidos externos y vibraciones del fonógrafo | ⇔ | Código Genético (correspondencia entre tripletes de ARNm y aminoácidos) |
| desbaratamiento del fonógrafo | ⇔ | destrucción de la célula |
| Título de la canción especialmente elaborada para el Fonógrafo X: “No puedo ser escuchado mediante el Fonógrafo X” | ⇔ | Interpretación de alto nivel de la cadena de ADN especialmente elaborada para la Célula X: “No puedo ser replicada por la Célula X” |
| Fonógrafo “Imperfecto” | ⇔ | Célula para la cual existe por lo menos una cadena de ADN que no puede reproducir |
| “Teorema Tortuguiano”: “Siempre existe un disco inejecutable, dado un fonógrafo determinado”. |
⇔ | Teorema de la Excepción: “Siempre existe una cadena de ADN irreproducible, dada una célula determinada”. |
La analogía con el Teorema Gödeliano tiene que ser considerada como un hecho singular, probablemente no muy provechoso para los biólogos moleculares (para quienes ello resultará sin duda bastante obvio):
Siempre es posible diseñar una cadena de ADN que, en caso de ser introducida en una célula, al ser transcripta, generaría la producción de proteínas que destruirían la célula (o el ADN), de lo cual resultaría la no reproducción de ese ADN.
Esto despierta una imagen más bien graciosa, por lo menos desde la perspectiva de la evolución: una especie invasora de virus ingresa a una célula valiéndose de ciertos recursos subrepticios y, a continuación, ¡se asegura prolijamente de que sean producidas proteínas cuyo efecto consista en destruir ese mismo virus! Es una forma de suicidio —o de enunciado de Epiménides— en el nivel molecular. Obviamente, esto no significaría una ventaja desde el punto de vista de la supervivencia de la especie. Sin embargo, sirve para demostrar el espíritu, si no la letra, de los mecanismos de protección y de subversión que han desarrollado las células y sus invasores.
Pasemos a ver ahora la célula predilecta de los biólogos, la de la bacteria Escherichia coli (carece de toda relación con M. C. Escher), y también uno de los invasores más frecuentes de esa célula, el siniestro y misterioso bacteriófago T4, que aparece ilustrado en la figura 101. (Dicho al margen, las palabras “fago” y “virus” son sinónimas, y significan “agresor de las células bacteriales”). Este fantástico bichito se parece a una cruza entre un módulo destinado a paseos lunares y un mosquito, y es mucho más temible que este último. Tiene una “cabeza” que almacena toda su “sabiduría”: a saber, su ADN; y seis “patas” de las que se vale para adherirse a la célula que ha decidido invadir; también cuenta con un “aguijón” (más propiamente llamado “cola”), igual que un mosquito. La diferencia más visible es que, a diferencia de éste, el cual utiliza su aguijón para succionar sangre, el fago T4 lo utiliza para inyectar su sustancia hereditaria en el interior de la célula, y contra lo que serían los deseos de su víctima. De este modo, el fago comete “violación”, en escala minúscula.
FIGURA 101. El virus bacterial T4 es un ensamblamiento de componentes proteínicos (a). La “cabeza” es una membrana proteínica, de forma de icosaedro alargado hacia los polos, compuesto por treinta caras, y lleno de ADN en su interior. Un cuello lo une a una cola que consiste en un eje vacío rodeado por una vaina contráctil que termina en una placa con salientes como pernos que le sirve de base, y a la cual van adheridas seis fibras. Los pernos y las fibras fijan el virus a una pared celular bacterial (b). La vaina se contrae, haciendo que el eje atraviese la pared, y entonces el ADN viral ingresa en la célula. [Tomado de Hanawalt and Haynes, The Chemical Basis of Life, p. 230.]
¿Qué sucede, realmente, cuando el ADN viral penetra en una célula? El virus “confía”, para hablar antropomórficamente, en que su ADN reciba exactamente el mismo tratamiento que el ADN de la célula huésped. Esto significará que ha de ser transcripta y traducida, lo cual le permitirá dirigir la síntesis de sus propias proteínas específicas, extrañas a la célula huésped, las cuales comenzarán entonces a realizar su tarea. Esta equivale al transporte secreto de las proteínas “en código” (es decir, el Código Genético) hasta dentro de la célula, y a su posterior “decodificación” (es decir, a su producción). En cierta forma esto nos hace presente el episodio del caballo de Troya: cientos de soldados se introdujeron en Troya sin ser vistos, escondidos dentro de un inmenso caballo de madera fabricado con ese fin; una vez en el interior de la ciudad, abandonaron su escondite y la capturaron. Las proteínas extrañas, luego de “decodificadas” (sintetizadas) a partir de su ADN transportador, se lanzan a la acción. La secuencia de acciones dirigidas por el fago T4 ha sido cuidadosamente estudiada y es aproximadamente como sigue (véanse también las figuras 102 y 103):
| Tiempo transcurrido | Acción que tiene lugar |
|---|---|
| 0 min. | Inyección de ADN viral. |
| 1 min. | Trastorno del ADN huésped. Cese de la producción de proteínas nativas e iniciación de la producción de proteínas extrañas (T4). Entre las primeras proteínas producidas se cuentan las que dirigen la replicación del ADN extraño (T4). |
| 5 min. | Comienza la replicación de ADN viral. |
| 8 min. | Iniciación de la producción de proteínas estructurales que forman los “cuerpos” de los nuevos fagos. |
| 13 min. | Es producida la primera réplica completa del T4 invasor. |
| 25 min. | La lisozima (una proteína) ataca la pared celular, rompe la bacteria, y emergen los “bicentupletes”. |
De tal modo, cuando un fago T4 invade una célula de E. coli, pasado un breve lapso de entre veinticuatro y veinticinco minutos esa célula ya se encuentra totalmente subvertida, y rota. Surgen entonces aproximadamente doscientas copias exactas del virus original —“bicentupletes”—, prestas a atacar otras células bacteriales; la célula original, en este momento, ya ha sido consumida por el proceso.
FIGURA 102. La infección viral comienza cuando el ADN viral penetra en una bacteria. El ADN bacterial es desordenado y se produce la replicación del ADN viral. La síntesis de las proteínas virales estructurales y su reunión en el virus prosigue hasta que la célula es destruida, y deja partículas en libertad. [Tomado de Hanawalt and Haynes, The Chemical Basis of Life, p. 230.]
Aunque esto, desde el punto de vista de una bacteria, signifique una amenaza fatal, desde nuestro punto de observación atento a la gran escala podemos considerarlo como un entretenido juego entre dos oponentes: el invasor, o jugador “T” (llamado después clase par de fatos T, la cual incluye al T2, al T4, y otros), y el jugador “C” (abreviatura de “Célula”). El objetivo del jugador T es invadir la célula del jugador C, y hacerse cargo de ella desde dentro, con la finalidad de autorreproducirse. El objetivo del jugador C es defenderse y destruir al invasor. Descripto de esta manera, el juego molecular TC puede ser visto como enteramente análogo al juego macroscópico TC mencionado en el Diálogo precedente. (Sin duda, el lector puede determinar cuál jugador —T o C— se corresponde con la Tortuga, y cuál con el Cangrejo).
Este “juego” subraya el hecho de que uno de los temas centrales de la biología celular y subcelular es el “reconocimiento”. ¿Cómo se reconocen entre sí dos moléculas (o estructuras de nivel más alto)? Es esencial, para el funcionamiento de una enzima, que pueda restringir su “sitio de combinación” específico al uso exclusivo del mismo por sus sustratos; es esencial que una bacteria pueda distinguir entre su propio ADN y el de los fagos; es esencial que dos células puedan reconocerse entre sí, e interactuar de una manera controlada. Tales problemas de reconocimiento puede que nos recuerden el problema inicial y clave de los sistemas formales: ¿cómo poder determinar si una cadena tiene o no tiene una propiedad en particular, como por ejemplo la teoremidad? ¿Existe un procedimiento de decisión? Este género de interrogaciones no están circunscriptos al ámbito de la lógica matemática: lo encontramos en la ciencia de las computadoras y, según vemos, también en la biología molecular.
La técnica de rotulamiento descrita en el Diálogo es, en realidad, uno de los recursos utilizados por la E. coli para sacar ventaja sobre sus fagos invasores. La idea consiste en que las cadenas de ADN pueden ser rotuladas químicamente adhiriendo una pequeña molécula —metilo— a diversos nucleótidos. Pero esta operación de rotulamiento no modifica las propiedades biológicas habituales del ADN; en otras palabras, el ADN metilado (rotulado) puede ser transcrito exactamente igual que el ADN no metilado (no rotulado), y dirigir, en consecuencia, la síntesis de las proteínas. Así, si la célula huésped cuenta con un mecanismo especial que examine si el ADN está rotulado o no, el rótulo se convierte en la diferencia más importante del mundo. Específicamente, la célula huésped puede tener un sistema enzimático que ubique al ADN no rotulado, y lo destruya allí donde lo encuentre partiéndolo despiadadamente en pedazos. En tal caso, ¡guay de todos los invasores no rotulados!

FIGURA 103. El tránsito morfogenético del virus T4 consta de tres ramas principales que llevan independientemente a la formación de la cabeza, la cola y las fibras, luego combinadas para dar lugar a partículas completas del virus. [Tomado de Hanawalt y Haynes, The Chemical Basis of Life, p. 237.]
Los rótulos de metilo en los nucleótidos han sido comparados con los menudos trazos que rematan los extremos de ciertos tipos de imprenta (cuyo nombre técnico es serif). Convirtiendo esto en metáfora, podríamos decir que la célula E. coli ha de buscar el ADN que esté escrito en su “tipografía local”, utilizando su tipo de letra peculiar, y que destruirá cualquier cadena de ADN escrita en una tipografía “ajena”. Una contraestrategia posible, desde la perspectiva de los fagos, consistiría por supuesto en aprender a autorrotularse, con lo que inducirían a las células a las cuales están invadiendo a reproducirlos.
Esta batalla TC puede llegar a extenderse hasta niveles discrecionales de complejidad, pero no perseguiremos estas posibilidades. El hecho esencial es que aquí se trata de una guerra entre un huésped que está esforzándose por rechazar por completo al ADN invasor, y un fago que intenta infiltrar su ADN en un huésped que lo transcribirá en el ARNm (con lo cual queda garantizada su reproducción). A todo ADN fago que consiga ser reproducido en esta forma puede aplicarse esta interpretación de alto nivel: “Puedo ser reproducido en Células del Tipo X”. Esto se distinguiría del caso del evolutivamente descaminado género de fago al que aludimos más atrás, el cual codifica proteínas para su propia destrucción, y cuya interpretación de alto nivel sería esta confesión de derrota: “No puedo ser reproducido en Células del Tipo X”.
Ahora bien, estos dos tipos opuestos de autorreferencia en biología molecular tienen su equivalente en lógica matemática. Ya hemos hablado del término análogo a los fagos que se autoanulan: a saber, las cadenas del tipo Gödel, las cuales afirman su propia improducibilidad en el interior de los sistemas formales. Pero también es posible elaborar un enunciado equivalente a un fago real: el fago afirma su propia producibilidad en una célula específica, y el enunciado afirma su propia producibilidad en un sistema formal específico. Los enunciados de esta clase reciben el nombre de Henkin, en homenaje al lógico matemático Leon Henkin; se los puede construir siguiendo con exactitud las líneas de los enunciados Gödel, con la única diferencia de la omisión de la negación. Se comienza, naturalmente, con un “tío”:
∃a:∃a′:<PAR DE PRUEBA TNT{a,a′}∧ARITMOQUINEREAR{a″,a′}>
Se sigue luego con el recurso habitual. Digamos que el número Gödel del “tío” precedente es h; por quinereamiento de este mismo tío, obtenemos un enunciado Henkin:

(Al margen, ¿el lector puede señalar en qué difiere de ~G este enunciado?). La razón que he tenido para mostrar explícitamente un enunciado de Henkin es la de puntualizar que éste no brinda una fórmula completa de su propia derivación; se limita a afirmar que existe una fórmula así. Es posible preguntarse si tal afirmación tiene fundamento: ¿los enunciados de Henkin, en realidad, cuentan con derivación? ¿Son, como pretenden, teoremas? Es útil recordar que uno no tiene por qué dar crédito a un político que diga, “Soy honesto”: puede que sí lo sea, y también puede que no lo sea. ¿Los enunciados de Henkin son más dignos de crédito que los políticos?
Pero resulta que estos enunciados de Henkin son invariablemente veraces. No es algo obvio verlo así, pero aceptaremos este curioso hecho sin pedir pruebas.
Ya mencioné que un enunciado de Henkin no dice nada acerca de su propia derivación: sólo afirma que existe una. Pero es posible inventar una variación sobre el tema de los enunciados de Henkin, a saber: enunciados que describan explícitamente su propia derivación. La interpretación de alto nivel de un enunciado así no sería “Existe alguna secuencia de cadenas que es una derivación mía”, sino “La secuencia de cadenas descripta aquí… es una derivación mía”. Llamemos al primer tipo de enunciado un enunciado implícito de Henkin; los otros enunciados serán llamados enunciados explícitos de Henkin, puesto que describen explícitamente su propia derivación. Adviértase que, a diferencia de sus camaradas implícitos, los enunciados explícitos de Henkin no tienen por qué ser teoremas. En realidad, es sumamente sencillo formular una cadena que afirme que su propia derivación consiste en la cadena única O=O: una afirmación falsa, ya que O=O no es derivación de ninguna cosa. Sin embargo, también es posible formular un enunciado de Henkin explícito que sea un teorema, esto es, un enunciado que aporte efectivamente una receta para elaborar su propia derivación.
Presento esta distinción entre enunciados de Henkin explícitos e implícitos porque se corresponde muy ajustadamente a una significativa distinción entre tipos de virus. Existen algunos de éstos, como el ya citado virus del mosaico del tabaco, denominados virus autoensambladores; y hay otros, como nuestros T pares, que son no autoensambladores. ¿Y qué pasa con esta distinción? Tiene una analogía directa con la que separa a los enunciados implícitos de Henkin de los explícitos.
El ADN de un virus autoensamblador codifica únicamente las partes de un nuevo virus, pero no las enzimas. Una vez producidas las partes, el ruin virus confía en que las mismas se ligarán entre sí, sin necesidad de ninguna colaboración enzimàtica. Tal proceso descansa en las afinidades químicas que existen entre las partes, allí en esa rica mezcla química de la célula, en la cual están nadando. No solamente los virus, sino también ciertos organelos —los ribosomas, por ejemplo— se autoensamblan.
En ocasiones, pueden hacer falta enzimas: en estos casos, son reclutadas dentro de la célula huésped y sometidas; éste es el significado de autoensamblar.
Por el contrario, el ADN de virus más complejos, como el de los pares, T codifica no sólo las partes sino, además, diversas enzimas que cumplen funciones específicas en el ensamblamiento de las partes para que constituyan conjuntos. Puesto que tal proceso de montaje no es espontáneo sino que requiere de “máquinas”, estos virus no son considerados autoensambladores. La esencia de la distinción, entonces, entre unidades autoensambladoras y no autoensambladoras consiste en que las primeras conquistan la autorreproducción sin dar ninguna indicación a la célula con respecto a la construcción de sí mismas, en tanto que las segundas necesitan dar instrucciones acerca de cómo ser ensambladas.
Pero el paralelo con los enunciados implícitos y explícitos de Henkin debe ser absolutamente claro. Los enunciados implícitos de Henkin son autoprobatorios, pero no dicen nada en absoluto con respecto a su prueba: son análogos a los virus autoensambladores; los enunciados explícitos de Henkin dirigen la construcción de su propia prueba: son análogos a los virus más complejos, los cuales instruyen a sus células huéspedes con respecto a cómo armar copias de ellos mismos.
El concepto de estructuras biológicas autoensambladoras de la complejidad de los virus origina la posibilidad de máquinas autoensambladoras igualmente complejas. Imaginemos un conjunto de partes que, cuando están situadas en el ámbito de sustentación adecuado, se agrupan de tal manera que integran una máquina compleja. Esto suena inverosímil, pero constituye sin embargo un medio preciso de descripción del método a través del cual el virus del mosaico del tabaco se autorreproduce por vía de autoensamblamiento. La información necesaria para la conformación total del organismo (o de la máquina) está diseminada en sus partes, y no concentrada en ninguna localización particular.
Ahora bien, este concepto puede conducir hacia extrañas direcciones, tal como fue mostrado en los Pensamientos edificantes de un fumador de tabaco. Allí, vimos que el Cangrejo manejaba la idea de que la información requerida para el autoensamblamiento puede estar esparcida en lugar de encontrársela concentrada en un solo sitio. Su esperanza era que ello evitaría una nueva destrucción de sus fonógrafos a manos del método rompefonógrafos de la Tortuga. Por desdicha, tal como pasa con los más refinados esquemas axiomáticos, una vez acabada en un todo la construcción del sistema y empacado éste en un cajón, su propio carácter de bien definido lo hace vulnerable frente a un “gödelizador” lo suficientemente talentoso; de esto trataba el triste relato del Cangrejo. Pese a su aparente absurdo, la situación fantástica de ese Diálogo no está tan lejos de la realidad en el misterioso y superreal mundo de la célula.
Ahora bien, el autoensamblamiento puede ser el recurso del que se valen ciertas subunidades celulares para ser construidas, y también ciertos virus, pero, ¿qué ocurre con las estructuras macroscópicas más complejas, como por ejemplo el cuerpo de un elefante o el de una araña, o la forma de cierta planta insectívora? ¿Cómo son construidos los instintos de orientación en el cerebro de un pájaro, o los de caza en el de un perro? En resumen, ¿cómo es que, simplemente mediante el dictado de cuáles proteínas han de ser producidas en las células, el ADN ejerce un control tan espectacularmente exacto sobre la estructura y la función precisas de los objetos vivos macroscópicos? Hay dos problemas principales aquí, de índole distinta. Uno es el de la diferenciación celular: ¿cómo diferentes células que comparten exactamente el mismo ADN cumplen diferentes funciones, sea la de célula renal, la de célula medular o la de célula cerebral, por ejemplo? El otro problema es el de la morfogénesis (“nacimiento de la forma”): ¿cómo da origen la comunicación intercelular de nivel regional a estructuras y organizaciones globales, de gran escala, tales como los diversos órganos del cuerpo, la forma del rostro, los subórganos del cerebro, etc.? Aunque la diferenciación celular y la morfogénesis son conocidas escasamente en la actualidad, la clave parece residir en mecanismos exquisitamente ajustados de retroalimentación y “prealimentación”, vigentes dentro de y entre las células, los cuales indican a éstas cuándo “encender” y cuándo “apagar” la producción de diversas proteínas.
La retroalimentación tiene lugar cuando alguna sustancia necesaria se encuentra en cantidad excesiva o escasa en la célula; ésta última debe entonces, de un modo u otro, equilibrar la línea de producción que está ensamblando dicha sustancia. La prealimentación también implica la regulación de una línea de montaje, pero no de acuerdo a la evaluación del producto fina] actual, sino a la evaluación de algún precursor del producto final de esa línea de montaje. Existen dos expedientes principales para la obtención de retroalimentación o prealimentación negativas: uno consiste en evitar que las enzimas pertinentes actúen; es decir, en “tapar” sus lugares activos, lo cual es denominado inhibición; el otro, conocido como represión, ¡consiste en evitar que las enzimas pertinentes sean manufacturadas! Conceptualmente, la inhibición es simple: basta con bloquear el sitio activo de la primera enzima de la línea de montaje; ello paraliza el proceso íntegro de síntesis.
La represión es más compleja. ¿Cómo interrumpe una célula la expresividad de un gen? Impidiendo que sea transcripto, es la respuesta; esto significa que ha de evitarse la realización de su tarea por parte de la polimerasa ARN. Esto se puede conseguir mediante la implantación de un gran obstáculo en su camino, a lo largo del ADN, exactamente delante del gen que la célula no quiere que sea transcrito. Tales obstáculos existen y son llamados represores; son, a su vez, proteínas, y se adhieren a sitios específicos de fijación de obstáculos en el ADN, denominados (no sé bien por qué) operadores. Un operador, en consecuencia, es un sitio de control del gen (o genes) que viene inmediatamente detrás y al cual se identifica como el operón de aquél. Ya que, frecuentemente, una serie de enzimas se conciertan para efectuar una transformación química extensa, pueden ser codificadas en secuencias; de ahí que muchas veces los operones contengan diversos genes y no solamente uno. Cuando se logra la represión de un operón, el resultado consiste en que se impide la transcripción de una serie completa de genes, lo cual significa que un conjunto completo de enzimas interrelacionadas queda sin sintetizar.
¡Y qué diremos de la retro y la prealimentación positivas! Aquí encontramos también dos opciones: (1) el destape de las enzimas taponadas, o (2) el cese de la represión ejercida por los operones pertinentes. (Tómese nota de que la naturaleza, aparentemente, ¡ama la doble negación! Es probable que haya alguna razón profunda para ello). El mecanismo a través del cual es reprimida la represión abarca una clase de moléculas llamadas inductoras\ la función de un inductor es simple: se combina con una proteína represora antes de que ésta haya tenido oportunidad de unirse a un operador, en una molécula de ADN; el “compuesto represor-inductor” es incapaz de unirse a un operador, y esto deja abierta la puerta para que el operón asociado sea transcrito a ARNm y, a continuación, traducido a pro teína. En ocasiones, el producto final o algún precursor del producto final pueden actuar como inductores.
Ya que estamos, éste es un momento excelente para distinguir entre clases simples de retroalimentación, como las de los procesos de inhibición y represión, y los bucles que abrazan diferentes niveles de información, mostrados en el Correspondogma Central. Ambos son “retroalimentación”, en algún sentido, pero en el segundo caso hay mucha mayor profundidad que en el primero. Cuando un aminoácido, como por ejemplo el triptófano o la isoleucina, actúa como retroalimentador (bajo la forma de inductor), combinándose con su represor para lograr eficacia, no está indicando cómo debe ser construido en función retroalimentadora sino, solamente, está dando indicaciones en ese sentido a las enzimas. Esto podría ser comparado al volumen de un aparato de radio que alimenta el oído de un oyente, lo cual puede causarle el efecto de ser subido o bajado. Es algo totalmente distinto al caso de una emisora que indique explícitamente que el receptor de radio debe ser encendido o apagado, o sintonizado en otra longitud de onda o, inclusive, ¡cómo construir otro receptor! Esto último es muy semejante a los bucles comprensivos de diferentes niveles de información, pues la información contenida en la señal radiotelefónica es “decodificada” y traducida a estructuras mentales. Dicha señal está compuesta por constituyentes simbólicos, cuya significación simbólica es de aplicación a la situación: un caso de uso, no de mención. Por el otro lado, cuando el sonido es estrepitoso, los símbolos no están transmitiendo significados; son percibidos meramente como sonidos estrepitosos, y muy bien podrían estar vacíos de significación: un caso de mención, no de uso. Este ejemplo es más próximo a los bucles de retroalimentación a través de los cuales las proteínas regulan sus valores de síntesis.
Existe la explicación de que la diferencia entre dos células contiguas que comparten exactamente el mismo genotipo y, pese a ello, cumplen funciones diferentes, se debe a que diferentes segmentos de su genoma han sido reprimidos, y por consiguiente tienen diferentes juegos operativos de proteínas. Tal hipótesis puede dar razón de las extraordinarias diferencias entre las células de los distintos órganos de un cuerpo humano.
El proceso por el cual una célula inicial se replica una y otra vez, dando lugar a una miríada de células diferenciadas que cumplen funciones específicas, puede ser comparado a la difusión persona a persona de una carta en cadena, donde se solicita a cada participante que repita el mensaje con fidelidad, pero también que agregue un toque personal. Al final, habrá cartas que guarden una tremenda diferencia entre sí.
Otra ilustración de la noción de diferenciación es provista por una computadora sumamente simple, análoga a una autorrep diferenciadora: supongamos un programa muy breve, controlado por un conmutador de dos posiciones —superior e inferior— y dotado de un parámetro interno N: un número natural. Este programa funciona a través de dos modalidades, señaladas por las dos posiciones mencionadas del conmutador. Cuando lo hace en la modalidad superior, se autorreplica en una parte adyacente de la memoria de la computadora, con la excepción de que el parámetro N de su “hija” es más grande en la réplica. Cuando lo hace en la modalidad inferior, no se autorreplica sino que, en lugar de ello, calcula el número
(−1)N/(2N + 1)
y lo suma a un procesamiento total.
Bien, supongamos que, en el comienzo, hay una copia del programa en la memoria, N = 0, y que la modalidad es la superior. El programa, entonces, se autocopiará en la puerta contigua de la memoria, con N = 1. Repitiendo el proceso, el nuevo programa se autocopiará en el sitio siguiente, mediante una copia que tenga N = 2. Y así siguiendo, una y otra vez… Lo que ocurre es que se está desarrollando un programa muy extenso en la memoria. Cuando ésta se complete, el proceso se detendrá. En este momento, puede considerarse que el conjunto de la memoria contiene un gran programa, compuesto por muchos módulos, o “células”, similares pero diferenciados. Supongamos ahora que conmutamos el programa a la modalidad inferior y procesamos este gran programa. ¿Qué sucede? Es pasada la primera “célula”, y calcula 1/1; luego la segunda “célula”, la cual calcula −1/3 y lo agrega al resultado anterior; luego la tercera “célula”, la cual calcula +1/5 y lo suma… El resultado final consiste en que el “organismo” total —el gran programa— calcula la suma
1 – 1/3 + 1/5 – 1/7 + 1/9 – 1/11 + 1/13 – 1/15 + …
de un gran número de términos (tantos términos como “células” puedan caber en la memoria). Y, como esta serie tiende (aunque lentamente) a π/4, tenemos un “fenotipo”, cuya función es calcular el valor de una constante matemática célebre.
Confío en que la descripción de procesos como el rotulamiento, el autoensamblamiento, la diferenciación, la morfogénesis y los de transcripción y descripción hayan contribuido a comunicar cierta idea acerca del sistema inmensamente complejo que es una célula: un sistema de procesamiento de información, dotado de algunos sorprendentes rasgos adicionales.
Ya hemos visto en el Correspondogma Central que, si bien podemos intentar el trazado de una frontera clara entre programa y datos, la distinción es, en realidad, un tanto arbitraria. Avanzando en esta reflexión, hallamos que no solamente programa y datos se entretejen intrincadamente, sino que también el intérprete de los programas, el procesador físico e inclusive los lenguajes son incluidos en esta fusión íntima. En consecuencia, aunque es posible (en alguna medida) trazar límites que separen entre sí los niveles, no es menos importante —y fascinante— reconocer los cruces y entremezclamientos de niveles. Esto es ilustrado por el asombroso hecho de que, en los sistemas biológicos, todos los aspectos requeridos por la autorrep (lenguaje, programa, datos, intérprete y procesador) intervienen de tal manera que todos ellos son replicados en forma simultánea, lo cual muestra cuánto más profunda es la autorreplicación biológica que ninguna de las invenciones humanas en ese campo. Por ejemplo, el programa de autorrep presentado al principio de este Capítulo da por supuesta la existencia previa de tres aspectos externos: un lenguaje, un intérprete y un procesador, y no los replica.
Probaremos de resumir las diversas formas en que las subunidades de una célula pueden ser clasificadas en términos de ciencia de las computadoras. Comencemos con el ADN: puesto que éste contiene toda la información para regir la construcción de las proteínas, las cuales son los agentes activos de la célula, puede ser visto como un programa formulado en un lenguaje de mayor nivel, subsiguientemente traducido (o interpretado) al “lenguaje de máquina” de la célula (proteínas). Por otro lado, el ADN es, asimismo, una molécula pasiva sometida a las manipulaciones de diversos tipos de enzimas; en ese sentido, una molécula de ADN es exactamente igual a una extensa pieza de datos. En tercer lugar, el ADN contiene el molde que imprime las “tarjetas” de ARNt, lo cual significa que el ADN contiene, también, su propio lenguaje de más alto nivel.
Pasemos a las proteínas: son moléculas activas, que realizan todas las funciones de la célula; por lo tanto, es enteramente razonable considerarlas como programas del “lenguaje de máquina” de la célula (donde la célula misma es el procesador). En otro orden, como las proteínas son hardware y la mayor parte de los programas son software, tal vez sea más acertado pensar que las proteínas son procesadores. En tercer lugar, a menudo las proteínas reciben la acción de otras proteínas, lo cual significa que, en tales casos, las proteínas son datos. Por último, es posible entender a las proteínas como intérpretes: esto implica que el ADN ha de ser visto como una colección de programas en lenguajes de alto nivel, de lo cual se desprende que las enzimas se limitan a dar cumplimiento a los programas formulados en código ADN: a su vez, esto equivale a decir que las proteínas están actuando como intérpretes.
Tenemos luego a los ribosomas y a las moléculas ARNt: se trata de intermediadores a la traducción de ADN a proteínas, lo que puede ser comparado con la traducción de un programa en lenguaje de alto nivel a lenguaje de máquina; en otras palabras, los ribosomas están funcionando como intérpretes, y las moléculas de ARNt aportan la definición del lenguaje de nivel más alto. Pero hay un punto de vista alternativo a propósito de la traducción: los ribosomas pueden ser considerados procesadores, y las moléculas de ARNt, intérpretes.
Apenas si hemos arañado la superficie en este análisis de las interrelaciones que vinculan a todas las biomoléculas mencionadas. Lo que hemos percibido es que la naturaleza se siente muy cómoda mezclando niveles que nosotros tendemos a ver como totalmente distintos. En la ciencia de las computadoras, actualmente, existe ya una inclinación visible a fusionar todos estos aspectos aparentemente diferentes de un sistema de procesamiento de información. Esto se nota particularmente en la investigación sobre inteligencias artificiales, generalmente situada a la cabeza en cuanto a la invención de lenguajes de computadora.
Surge una pregunta natural, y fundamental, después de conocer estas piezas de software y hardware increíblemente entrelazadas: “¿Cómo empezó esto?”. En verdad, se trata de un asunto desconcertante. Uno tiene que imaginarse la aparición de una suerte de proceso de “gancho”, en cierto modo semejante al empleado en el desarrollo de lenguajes nuevos de computadora… pero un gancho que lleve desde la molécula simple hasta la célula completa está prácticamente más allá del poder de nuestra imaginación. Hay más de una teoría a propósito del origen de la vida. Todas quedan varadas en la pregunta más fundamental: “¿Cómo se origina el Código Genético, junto con sus mecanismos de traducción (ribosomas y moléculas ARNt)?”. Por el momento, debemos conformarnos con un sentimiento de asombro y de reverencia, antes bien que con una respuesta. Experimentar ese sentimiento quizá sea más satisfactorio que contar con una respuesta, al menos por un tiempo.