Uno de los servicios de la compañía, accesible desde su página principal, es Google News. Fue incorporado en 2002 y lo definen como «una herramienta que rastrea e indexa la información contenida en centenares de medios de comunicación de todo el mundo y ofrece a los usuarios la posibilidad de buscar datos en ellos». Los sitios web de estos medios de comunicación se rastrean frecuentemente, por lo que resulta factible incluso encontrar noticias publicadas hace pocos minutos.
Desde la puesta en circulación de este servicio, algunos medios se han quejado de su relación directa con un acusado descenso del tráfico en sus servicios web y, por lo tanto, con la pérdida de sus ingresos por publicidad. Agencias de noticias, medios de comunicación y asociaciones de fotógrafos han visto menoscabados sus derechos de propiedad intelectual, por lo que algunos de ellos se han visto obligados a acudir a los tribunales.
Una de esas demandas fue impuesta en 2005 por la agencia francesa Agence France-Presse (AFP) por incluir noticias sin su permiso. Exigía por ello un pago de 17,5 millones de dólares y una orden para que Google se abstuviera de reproducir tanto los textos como los titulares y las fotografías de su propiedad. Tal y como figuraba en su apelación, «Google ha ignorado todos los requerimientos para cesar en su actividad, lo que constituye una violación del copyright de AFP». Por ese motivo la citada agencia presentó una demanda ante los tribunales de Estados Unidos y Francia. Finalmente, en 2007 llegaron a un acuerdo económico y la agencia autorizó a Google News para que continuara publicando sus contenidos. Como ocurre casi siempre con Google cuando llegan a acuerdos en procesos judiciales, los términos no se hicieron públicos.
Google no sólo ha tenido problemas con las agencias de noticias por su nuevo servicio. En Bélgica la batalla entre el buscador y la asociación de medios del país, Copiepresse, trajo serias consecuencias para esta última. Todo comenzó en 2006, cuando un grupo de periódicos demandó a Google con motivo de la utilización en Google News de los titulares y la información de noticias sin su permiso.
Ante la demanda, Google optó por dejar de utilizar el contenido, decisión que mantuvo durante un cierto período de tiempo. Pero en 2007, de forma sorprendente, volvió a incluir sin permiso el contenido en sus resultados. El juez encargado del caso nombró a un experto en internet, Luc Golvers, para que determinara si el producto de Google era un portal agregador de noticias, como sostenían los editores, o un simple producto de búsqueda. El informe de Golvers determinó que la forma de operar de la empresa perjudicaba gravemente a los editores y les hacía perder el control de sus portales digitales, así como de los contenidos en ellos publicados.
En mayo de 2011, un tribunal de Bruselas ratificó la prohibición impuesta a Google News de replicar la información de diversos periódicos belgas. Después de que el Tribunal de Apelaciones confirmara la victoria de Copiepresse, Google se vio obligado a cumplir con la sentencia judicial.
La sentencia del Tribunal de Apelación se apoyaba en una decisión judicial de septiembre de 2010 emitida por la Corte de Primera Instancia de Bruselas, aunque reducía de un millón a 25 000 euros la multa por cada día de retraso en la retirada de los contenidos de periódicos difundidos sin permiso. Google debería abonar una multa total de 3,25 millones de euros por los 130 días en los que hizo caso omiso a las reclamaciones y publicó sin la citada autorización contenidos en su sitio web.
Entonces sucedió algo inaudito: la compañía de Montain View no se limitó a eliminar los enlaces de Google News, sino que también suprimió todas las referencias a esos diarios… ¡en su índice de búsquedas! En otras palabras, en www.google.be, que tiene una posición de monopolio en las búsquedas de Bélgica, dejaron de aparecer las empresas denunciantes en los resultados de las búsquedas de los internautas. Así Google consumó su venganza al apagar de facto esos medios denunciantes en internet, ya que un importante número de sus lectores llega a ellos a través de los buscadores, y en Bélgica Google tiene más de un 90% de cuota de mercado. El perjuicio que se causó a los diarios belgas no tenía precedentes. Vieron con estupefacción cómo se desplomaba su número de visitantes de un día para otro, y con ello sus ingresos. La propia agencia se apresuró a declarar que, en realidad, su intención no era dejar de aparecer en el buscador, y que Google había restringido intencionadamente el tráfico a sus diarios como medida de presión por la sanción recibida y, evidentemente, como un ajuste de cuentas por la denuncia.
Hay que matizar ambas posturas para llegar a una comprensión clara del conflicto. Efectivamente, cualquier editor debería poder elegir si quiere que su información sea agregada a Google News. A mi entender, la compañía defiende de forma algo cínica que esto es así en cierto modo, porque «si hay quejas de alguien que se sienta agraviado, retiran el contenido». Pero esto no siempre es cierto. Además, es un razonamiento perverso que nos lleva a una particular interpretación de las normas más elementales de la propiedad intelectual. No es de recibo que una compañía no negocie, sino que simplemente coja lo que desee y, más adelante, si hay problemas, se preocupe de esos detalles. A esta forma de actuar, tan característica de Google que arrasa con todo sin el más elemental respeto a los demás, y que se cree con derecho a utilizar todo lo que se le ponga por delante, la definen en Estados Unidos con la expresión Don’t Ask Permission, Just Act (No pidas permiso, simplemente actúa).
El razonamiento de la compañía cuando les llegan los problemas y las quejas no deja lugar a dudas. «Sí, es cierto. Hemos agregado el contenido sin autorización previa. Pero os viene bien porque con ello, indirectamente, os enviamos trafico», parecen decir los mandamases de Google.
Si yo fuera propietario de uno de estos portales de noticias posiblemente querría estar incluido en Google News, ya que supone una fuente de tráfico extra. Pero me correspondería a mí decidirlo libremente, sin presiones, sin que nadie vulnere mis derechos tomando la decisión en mi lugar.
Ahora bien. Si, por el contrario, fuera una gran agencia de prensa o un gran grupo editor consolidado que monetiza estos contenidos por medio de su venta o de la publicidad, no querría que el consumo de información se llevase al portal de un tercero, en el que mi marca e identidad no existe ni se respeta, donde muchos usuarios leen un resumen de mis noticias sin necesitar más información —los lectores visitan Google News, consumen y se van—. Cualquier propietario de contenido debería ver respetados ciertos derechos, entre los que se encuentra decidir dónde, cómo y cuándo quiere que se difunda qué material. Ni Google ni nadie debería tener derecho a decidir sobre ello, ya que esto representa un abuso en sí mismo.
Existe además la figura del lucro cesante. Los usuarios fuera del medio editor no consumen publicidad. Por lo tanto, se genera una competencia desleal que hace que el editor, pese a ofrecer su información por medio de un tercero que lo parasita, no pueda mostrar sus anuncios, que es, en resumidas cuentas, su modus vivendi. Ha ofrecido un servicio, se ha menospreciado el valor de su marca y no ha obtenido nada a cambio.
¿Qué sería lo más razonable en este caso? Parafraseando a Aristóteles, tal vez la virtud esté en el justo medio. Google News es una herramienta magnífica para el usuario, pero cada editor debería elegir y negociar con ellos su presencia. No tiene sentido que Google lo imponga «a no ser que se quejen».
Sobre este servicio de noticias hay un dato al que se aferra la empresa para defender su actitud agresiva. A día de hoy el servicio no tiene publicidad, es decir, hasta la fecha no reciben ingresos publicitarios por su uso. Argumentan por activa y por pasiva que es un servicio sin ánimo de lucro y que, simplemente, trata de acercar la información a las personas e innovar en el consumo de noticias. En eso tienen algo de razón. Es un servicio útil, pero eso no justifica que para ofrecerlo vulneren derechos de terceros al utilizar sus contenidos en beneficio propio.
El hecho de que una compañía no esté lucrándose directamente de ese servicio —aunque puede que más tarde lo haga—, no quiere decir que no esté siendo capitalizado de otras maneras. Disponer de la información de los medios de comunicación en tiempo real y organizarla a su antojo hace que Google tenga ciertas ventajas que justifican el servicio. Por ejemplo, de ese modo se diferencia de la competencia y consigue ser un buscador todavía mejor, si cabe, lo que protege su posición de privilegio en internet. A su vez, el servicio los posiciona como un referente clave en la distribución de noticias respecto a los grandes grupos editoriales, lo que les permite tener poder de decisión sobre a quiénes envía más o menos tráfico, según la relación que mantenga con ellos, o según si son clientes de sus programas publicitarios. Por eso el discurso defensivo de la compañía hace aguas. Una cosa es no cobrar un servicio, o no rentabilizarlo de forma directa, y otra que no estés obteniendo beneficios indirectos, como información privilegiada, relación de dependencia de las empresas editoras hacia ti, poder, y posición más dominante aún en el mercado de las búsquedas y de la información.
Otro de los argumentos de defensa de Google News se fundamenta en defender que no están distribuyendo las noticias. Según ellos, sólo las ordenan e indexan para ayudar al internauta a acceder a la información. Sin embargo, una cosa es resumir una página web para listarla en un buscador, y otra bien distinta es hacerlo con una noticia, especialmente si es de pago y está distribuida por una agencia de información, cuyo modelo de negocio consiste en cobrar por la suscripción a ese tipo de contenido.
Google tiene la suerte de que su tamaño, su poder y sus tentáculos en todo tipo de segmentos de internet hacen que haya tantos intereses cruzados que generalmente les permiten maniobrar y llegar en el último momento a acuerdos que eviten males mayores. Por ejemplo, en el mencionado conflicto belga entre los medios de comunicación y la compañía de internet, los primeros se vieron obligados a retirar su demanda, tras lo cual los diarios volvían a aparecer en el buscador tras un fin de semana de «castigo». Los interesados interpretaron la noticia de la siguiente forma: Google y los diarios belgas habían «firmado la paz». Nada más lejos de la realidad. Se trató de una inmediata rendición de los editores de dichos diarios. Y esto es sólo un aviso y una muestra de la fuerza de un gigante poderoso respecto al sector de los medios de comunicación en general, un mensaje en el que muestra una posición preponderante y enseña sus armas ante futuros ataques a su servicio recordando a los se atrevan a llevarles la contraria que puede eliminar o limitar el acceso no sólo a su servicio de noticias, sino al buscador, lo que en muchos países, dada su cuota de mercado, significa literalmente desaparecer de internet. Eso es precisamente lo que no querían los medios belgas agrupados en Copiepresse. Tan sólo intentaban que Google pagara por su uso y, aunque ganaron y vieron reflejado su derecho judicialmente, la cantidad fue irrisoria en comparación con lo que perdían si Google les hacía desaparecer de su buscador. ¿Cómo se llama a esto popularmente? ¡Ah sí, chantaje! Tras un ignominioso arrepentimiento, Copiepresse ofreció garantías «de poder incluir de nuevo sus páginas» en el motor de búsqueda «sin que se apliquen las sanciones ordenadas por la justicia», según informaron en un comunicado oficial. Vamos, que han bajado las orejas tras las numerosas collejas recibidas. Moraleja: no se puede echar un pulso al imperio, ¡sobre todo si dependes de él!
Y es que una parte importantísima de las visitas de los medios de comunicación en internet llega directamente desde Google. Según algunos cálculos, entre el 15 y el 60% del total de sus visitantes lo hacen a través del buscador. En líneas generales, cuanto mayor es el poder de marca del medio y su reflejo social offline, menos dependencia teórica tiene del buscador, ya que un mayor número de personas accederán directamente a su página principal por medio de su portada, y no a través de Google. Pero, aunque así sea, los medios tienen cada vez más información almacenada en el índice de Google. Millones de usuarios utilizan el servicio de búsqueda, por lo que la dependencia es cada vez mayor. Es simple aritmética: más contenido del medio almacenado, más gente busca información. Aunque el medio tenga una legión de fieles, más personas accederán desde las búsquedas progresivamente, por lo que cada día dependen un poco más de Google que el anterior.
Aun no teniendo demasiado interés en Google News, muchas publicaciones lo toleran para evitar males mayores con la compañía que les provee de tráfico y, en algunas ocasiones, de ingresos con su programa de publicidad. Es difícil negarse a algo, por injusto que sea, cuando dependes tanto del prestador del servicio. En esas circunstancias, «NO» hay negociación posible. Sólo te queda el acatamiento.
Sin embargo, algunos medios de comunicación valoran el servicio tal cual lo presentan sus promotores. Consideran que el consumo de contenido informativo se realiza a modo de tráiler de película. Si al usuario le gusta lo que ve, con suerte terminará de leerlo en su contexto original. Pero ¿ocurre realmente así? Google defiende que te ayuda promocionando tu medio. Aunque no dispongas de «tráiler promocional» de tu información lo hacen ellos mismos y lo ofrecen a millones de usuarios. Eso provoca colateralmente que los generadores de contenido pierdan el control de cómo quieren que se muestre o se resuma su información.
También resultan habituales los materiales promocionales en la industria audiovisual. Siempre son producidos por el dueño de la obra sin que nadie pueda alterarla. En ocasiones ocurren situaciones esperpénticas con los derechos de propiedad. Te citaré como ejemplo un conflicto rocambolesco que se gestó hace algunos años en uno de nuestros portales de cine. Nos llegó por correo electrónico el adelanto promocional de una película. Se trataba de la última producción del director español Julio Medem que se estrenaba en las siguientes semanas bajo el título Habitación en Roma, protagonizada por Elena Anaya y Natasha Yarovenko. Eso es algo habitual. Recibes el tráiler unas semanas antes, lo publicas y tus visitantes lo ven en primicia, lo que suscita expectación de cara al estreno. La situación era completamente normal, por lo que lo que publicamos como hacemos con frecuencia. Pocos días más tarde me quedé perplejo al recibir un burofax de los representantes legales de la productora de la película instándonos a eliminar inmediatamente el vídeo de internet bajo la amenaza de emprender acciones legales. Según ellos, había sido «robado y filtrado sin su permiso». Me desconcertó tanto que me sentí utilizado. Era un material promocional y nos habían usado como vehículo de promoción gratuita —a lo que nosotros accedimos encantados por ser parte del juego y un valor añadido para nuestros visitantes—. Cuando se filtró y fue visto por miles de internautas nos obligaban a retirarlo, incluso con amenazas. Entonces, ¿para que habían hecho el tráiler? ¡Si sirven precisamente para eso, para usarlos en la promoción! En aquel momento hice una consulta a nuestro Departamento Legal. ¿Por qué debíamos retirarlo si se trataba precisamente de su difusión con fines promocionales? Para mi sorpresa, nuestro equipo jurídico recomendó retirarlo, ya que «pese a que es un material promocional, los autores tienen derecho a decidir cuándo, dónde y cómo se utiliza, teniendo que autorizar expresamente su publicación y pudiendo negarse a su antojo». Conclusión: lo eliminamos. Eso sí, lo que consiguieron fue que no habláramos más de la película, a pesar de que semanas más tarde nos invitaron a hacerlo. Esto no sólo nos sucedió a nosotros, sino también a decenas de otras páginas web especializadas. Muchas de ellas no conservan un especial cariño hacia el director y la productora tras el conflicto, y dudo que esta última reciba en el futuro desinteresadas ofertas de colaboración por parte de muchos portales especializados, como fue nuestro caso.
Volvamos a los problemas de Google News con diversos medios de comunicación. En marzo de 2010, el economista jefe de Google, Hal Varian, intentó calmar la inquietud que se empezaba a palpar ante la dependencia de Google. Por otro lado, intentó que los grandes grupos comprendieran mejor sus intenciones. La compañía se presentó a sí misma como el gran aliado del sector editorial. Les ofrecería nuevas e innovadoras vías para distribuir su contenido y les daría la fórmula para rentabilizar las noticias adaptándolas a los nuevos tiempos. Vamos, que se presentaban como los salvadores del periodismo en la época digital. ¡Dios mantenga en su gloria a estos chicos por salvar el sector media, aunque cometan la pecata minuta de robar contenidos de terceros que no les corresponden!
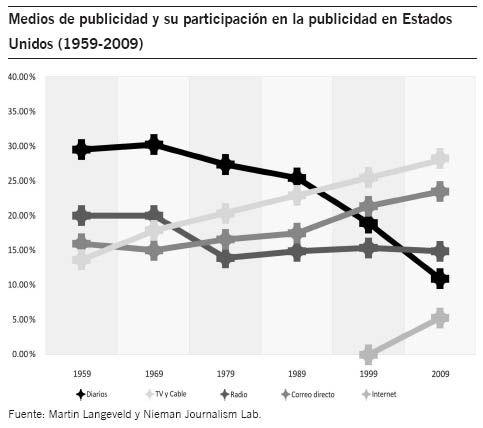
La prensa escrita está experimentando una caída de cuota en el mercado de la publicidad desde 1950 incluso en mercados maduros, como el de Estados Unidos. Tanto es así que hace medio siglo su cuota de mercado estaba en torno al 37% del global de la inversión, y hoy en día está en torno al 13, como se puede ver en el siguiente gráfico.
Poco pueden hacer desde la prensa escrita respecto al avance de la televisión. Aun así, la llegada de internet les pone en disposición de ofrecer contenido adaptado desde sus redacciones y en nuevos formatos. Es ahí donde Google quiere su parte del pastel, para lo cual se ofrece como el aliado clave.
Uno de los críticos más duros contra la posición de Google desde los medios de comunicación es el controvertido magnate australiano Rupert Murdoch, propietario de The Sun, The Times y The Wall Street Journal. En 2009 aseguró que estaban esperando a que todos sus medios fueran de pago en internet para cortarle el grifo a Google. Y no sólo eso. En reiteradas ocasiones se ha referido a la empresa acusándola de expolio de sus contenidos. Con ello ha logrado finalmente que el buscador renuncie a difundir noticias de periódicos que requieren suscripción. En 2009, Murdoch llegó a presentar sus quejas ante la Comisión Federal de Comercio en Washington. En su comparecencia acusó de robo a los que, como Google, utilizan las noticias de medios convencionales «sin contribuir con un solo céntimo a su producción». El editor exigió que se cambiase el modelo de negocio de los medios en internet, especialmente el de actores como Google. «Hay que transmitir a los consumidores que las informaciones de calidad y fiables no pueden ser gratuitas, porque el buen periodismo es un bien caro», espetó. Del mismo modo, las empresas del magnate australiano firmaron un acuerdo con Microsoft para que pudiera suministrar sus noticias en exclusiva. ¿Por qué Google no, y sí Microsoft? Simple y llanamente, porque la compañía de Bill Gates se mostró comprensiva con el pago de los contenidos y accedió a la firma de un acuerdo de distribución de la información de sus medios.
Durante 2010, Murdoch agitó con fuerza la bandera antiGoogle animando a los medios de información de todo el mundo a la rebelión contra la «tiranía ejercida por Google y el indiscriminado uso de su contenido». Para Robert Thomson, editor de The Wall Street Journal, «Google literalmente devalúa todo lo que toca». Tener la información listada en el buscador hace que esta carezca de valor y que acabe convirtiéndose en una commodity.
Nunca he sabido a ciencia cierta si el dueño de News Corp. es un valiente o un temerario. Posiblemente tenga un poco de cada cosa, amén de que, tal vez por su edad, la generación de internet le queda algo lejana y no es consciente del tamaño y la importancia que ha adquirido su rival. Algunos de los negocios que ha realizado en los últimos veinte años le han convertido en el auténtico visionario del sector de los medios de comunicación. Otros de sus movimientos en el ámbito de la tecnología, como la compra de MySpace por 580 millones de dólares, y su posterior venta seis años más tarde por 35 millones de dólares, no nos dejan la misma impresión. Su enfrentamiento con Google no parece resultar rentable ni positivo para sus medios. Da la sensación de que Murdoch quiere asumir el rol de Don Quijote a sabiendas de que puede acabar mal parado tras su lucha contra tan poderosos molinos de viento.
Pese a ello, la cruzada de Murdoch promete seguir siendo encarnizada si se lo permiten los casos de las escuchas ilegales en sus medios, que ciertamente han mermado su credibilidad. Recientemente hizo un llamamiento a todos los medios de comunicación escritos para establecer el sistema de pago por visualizar sus contenidos a fin de que Google no pudiera acceder a ellos. Esto inquietó a los responsables de la compañía, temerosos de que los principales medios de comunicación constituyeran un frente común. Entonces, Eric Schmidt habló personalmente con Murdoch y con otros propietarios de grandes empresas periodísticas para suavizar el enfrentamiento. Desde Mountain View les ofrecieron alternativas para mejorar sus ingresos y adaptarse a los nuevos tiempos. Schmidt sostiene el criterio de que la prensa del futuro debe adaptarse a un nuevo escenario, y que debe monetizar sus contenidos a través de tres vías diferentes: por publicidad, con sistemas de suscripción y con micropagos. Curiosamente, Google está en disposición de ofrecerles un acuerdo para explorar todas y cada una de esas opciones. Así nació el servicio First Click Free, suscrito entre otros por The Wall Street Journal, que permite a todos los usuarios que encuentran en Google un documento o una noticia que exige suscripción ver el texto completo la primera vez, y todo ello sin que se hayan registrado ni suscrito. Sin embargo, cuando el usuario selecciona un enlace en la página original, se le puede exigir que inicie sesión o que se registre para poder seguir leyendo.
En un intento de defender su servicio de los ataques cada vez más frecuentes de los medios, Google destacaba en un comunicado que «Google News es una estupenda fuente de promoción para las empresas periodísticas, y envía alrededor de 100 000 clics cada minuto. Cada una de esas visitas es una oportunidad de negocio para mostrar anuncios, ganar lectores fieles y vender suscripciones. Nuestra labor es completamente consecuente con las leyes del copyright».
No seré yo, para mi desgracia, el que tenga capacidad de resolver la encrucijada ante la que se encuentran los medios hoy en día. Tampoco es ese el motivo de este libro. Pero sí me gustaría apuntar que la distribución de contenidos literarios, musicales o periodísticos ha quedado fuera de juego con la implantación masiva de internet. En estos sectores se da un margen de «prueba y error» cada vez más pequeño, y les quedan pocas oportunidades para averiguar qué tipo de experiencias cosechan resultados.
En España Google News está plenamente aceptado. Pese a todo, la Asociación de Editores de Prensa Diaria (AEDE) no descarta ninguna acción futura para defender sus intereses. Consideran que, según la legislación vigente, habría «argumentos legales suficientes» para actuar contra el buscador por posible vulneración de la Ley de Propiedad Intelectual y abuso de posición dominante en la publicidad online, tal y como sostenía Diego Solana, letrado del despacho Cremades & Calvo-Sotelo, en una entrevista concedida al diario Público en junio de 2010.
Uno de los pesos pesados del periodismo español, el director del diario El Mundo, Pedro J. Ramírez, ha sido especialmente beligerante con la labor de Google. Pedro es una de las voces más reputadas del periodismo español y está curtido en mil batallas. La versión online del diario que dirige, www.elmundo.es, es líder absoluto de la información en España. Para su director, la preocupación sobre las prácticas de Google surgió súbitamente hace años al ver la actitud que la compañía empezaba a mostrar hacia los medios. Me puso como ejemplo unas declaraciones ante el Senado estadounidense de Marissa Mayer, actual vicepresidenta de Producto de Búsqueda y Experiencia de Usuario. Ella hablaba de los medios como meros entes generadores de información que podría ser consumida en cualquier otro lugar, sin importarle la identidad de quién la generara, y sin ofrecer al periodista ni al medio más trascendencia que la de un mero intermediario. Para Pedro, «sin medios y sin periodistas no hay periodismo, y Google, con su algoritmo, no puede en ningún caso intentar rellenar ese vacío». Recuerdo que me contó una anécdota cuanto menos curiosa. Google celebra una cita anual conocida como Zeitgeist para debatir sobre el futuro del sector periodístico. En aquella ocasión, en 2009, la cita era en una casa solariega de la campiña inglesa. Entre los oradores invitados estaba el propio Pedro, único representante español, junto a otros pesos pesados internacionales, como el director general de la BBC, Mark Thompson, el presidente del conglomerado Vivendi, Jean-Bernard Lévy, el gurú Charlie Leadbeater, y Carolyn McCall, consejera delegada de The Guardian. Fueron precisamente McCall y el español quienes reclamaron el papel de los medios de comunicación no como instituciones que se atrincheran contra las novedades de la tecnología, sino como las únicas plataformas capaces de ofrecer contenidos de calidad en un tiempo donde proliferan quienes sacan partido del trabajo ajeno —en una clara alusión a Google, ante la incredulidad de Larry Page, allí presente—. Me contaba Pedro que en un momento dado «Larry Page se picó y, sintiéndose atacado, quiso entrar en un cuerpo a cuerpo poniendo a Wikipedia como ejemplo del por qué los medios no son imprescindibles». Según comentaba el fundador de Google, cualquiera podía acceder en este sitio web a la información que quisiera, y no tenía trascendencia quién la había creado. Lo único importante era, para él, la tecnología. El periodista español, que minutos antes había sido tremendamente duro con la actitud de Google al referirse a ellos como «los piratas no son los usuarios, son los agregadores», al ver que Page nombraba la Wikipedia, me contó una experiencia propia, divertida, que yo no conocía, y que en aquel momento debió impactar a los asistentes.
«Cuando mi hija se fue a estudiar al extranjero fui a visitar la universidad que había eligido. Allí conocí y congenié con la persona encargada de las admisiones. En un momento dado me comentó que durante el proceso de selección se habían informado sobre mí, y me mostraron dicha información. Cuando vi la procedencia de la fuente me sorprendió que fuera la versión inglesa de Wikipedia». Pedro recuerda que echó un vistazo a los documentos, temeroso de encontrar cualquier barbaridad, consciente como era de que no había una rúbrica profesional e independiente detrás, y de que podría haber sido escrita por cualquiera. La figura de Pedro J. Ramírez es controvertida. Es una persona que despierta odios y pasiones y, en buena lógica, llegó a esperar lo peor en la información a la que estaba accediendo.
«Sin embargo —continuaba Pedro—, para mi sorpresa, no estaba mal. Era… correcta. Aséptica y superficial, sí, pero más o menos correcta. Me sorprendió, esperaba lo peor… Lo curioso es que casi al final, cuando llegué al apartado de vida personal, decía que estaba divorciado, y que actualmente vivía una relación como amante… ¡de Ralph Lauren!»
Pedro recuerda el jolgorio y las risas de los asistentes y la situación comprometida de Page, que justo segundos antes había basado la explicación de su modelo de nuevo consumo de información en esas fuentes. No sé si por hacer sangre, o ya gustándose como genio y figura que es, el director de El Mundo explicó que «a la salida del evento le esperaba fuera en un coche Ralph Lauren, para salir a disfrutar de la ciudad», ante el pitorreo y la ovación generalizada de los asistentes.
Quizá dolido en su orgullo, Larry Page le prometió que conseguiría la dirección IP del autor de aquel vandalismo informático para identificarlo. Pedro no me confirmó si el envío se produjo, por lo que imagino que, afortunadamente, el tema no pasó a mayores. Sin embargo, su ofrecimiento no deja de ser inquietante. Si tan seguro estaba de conseguir una dirección IP que había publicado algo en un sitio ajeno a Google, como es Wikipedia, tendríamos motivos para una honda preocupación. En los países «serios» tan sólo un juez puede pedir que se identifique una dirección IP, y en este caso entiendo que era Wikipedia la que la tenía almacenada en sus servidores. Si Page, o cualquier otra persona, pudiera acceder a ella lejos del control judicial, sería cuanto menos… sorprendente.
Anécdotas al margen, los editores de diarios y Google no tienen más remedio que entenderse. Los editores necesitan consumidores, y eso es precisamente lo que le sobra a la empresa del colorido buscador. Sobre todo, los editores necesitan nuevas opciones y posibilidades de negocio, y Google puede facilitárselas. Son dos piezas del mismo puzle, y acabarán por vivir una relación, si no de igual a igual, sí al menos más equitativa que la que tienen hoy en día, que es cualquier cosa menos justa.
En su relación con la prensa, Google no se limita únicamente a mostrar los titulares de medios online y resumir su contenido. Tenían intenciones mucho más ambiciosas. En 2008 comenzó su proyecto de digitalizar el archivo histórico de los más importantes periódicos antiguos. Este servicio también se ofrecería desde Google News, y sería accesible desde las páginas web de los propios periódicos.
En 2006 escanearon diarios como The New York Times, Washington Post, Time y otros. En algunos casos, como The New York Times, las consultas son de pago. Google corría con el gasto de la digitalización, que se financiaba con ingresos publicitarios compartidos con la empresa editora. Este servicio sí que fue, en principio, bien acogido por los editores, a los que por fin se les ofrecía un modelo para «entrar en el negocio» mediante el cual ganaban todos, o al menos en el que estaba previsto compartir los beneficios, de manera que no se sentían utilizados.
¿Qué pretendía Google con este proyecto? ¿Poner a tu disposición toda la información mundial? ¡Si ya lo dijo Larry Page! No, ahora en serio. Lo que Google pretendía era, simple y llanamente, un paso más en su transformación hacia el monopolio de acceso a la información que quieren llegar a ser y apropiarse de ese contenido, que quedaría así vetado a su competencia. Google aspira a ser la gran hemeroteca del mundo, el custodio de toda nuestra información. Con ello ganan, por supuesto, ingentes cantidades de dinero. Pese a ser una idea menos romántica que la que en su día pregonó Larry Page, resulta perfectamente lícita.
La hemeroteca recibió la única oposición de las empresas especializadas en procesar y buscar contenidos para librerías, escuelas, museos e investigadores. Para ellas era una mala noticia. Si el servicio se popularizaba, su negocio dejaba de tener sentido de la noche a la mañana. Dejarían de recibir encargos de búsqueda y digitalización, ya que todo el material estaría a una búsqueda de distancia. ¡Mala suerte para ellas! Si Google pone los ojos en un segmento, provoca un terremoto en el que siempre hay víctimas colaterales. En este caso, parecía haberles tocado a ellos.
Al final tuvieron suerte. Según afirmaron en un comunicado oficial de mayo de 2011, la empresa decidió poner fin al proyecto para centrarse en otros relacionados con los medios de comunicación, especialmente Google One Pass. Para una vez que tenían licenciado el derecho de los contenidos, no iban a seguir adelante. ¿Cuál era el problema? Simplemente, que el negocio no estaba resultando tan interesante como preveían, por lo que el objetivo de hacer felices a los usuarios facilitándoles el acceso a la información quedaba en segundo plano. ¿Es eso lícito? En mi opinión, ¡totalmente! Es una estrategia empresarial a todas luces razonable. No ha sido rentable y, por lo tanto, se deja de invertir en ello. Correcto. Lo que sin duda no es ético es vender a los cuatros vientos la idea de que tu único centro de interés es el usuario, y que tu máximo objetivo es facilitar su acceso a la información mundial, como si eso fuera más propio de una organización sin ánimo de lucro que de una empresa, y luego seguir a pies juntillas criterios económicos que contradicen flagrantemente lo que pregonas.
Google quiere canalizar hasta tal grado la información histórica que en 2001 adquirió a Deja.com los grupos de noticias del archivo Usenet, es decir, los 650 millones de mensajes publicados en grupos de noticias, que representan algo así como la memoria histórica de internet previa a la masificación de la world wide web. Usenet se convirtió de esta manera en Google Groups. En Mountain View deben pensar, y con mucho acierto, que no hay mejor manera de almacenar y ordenar toda información que ser el propietario de la misma, pese a que esto pueda vulnerar a la competencia.
Google Books es un ambicioso servicio por el que, desde 2004, Google pretende digitalizar millones de libros en colaboración con editoriales, universidades y grandes bibliotecas. La idea se basa en la búsqueda del texto completo de los libros que Google escanea. El texto es convertido por medio de reconocimiento de caracteres y se almacena en una base de datos propiedad de Google. El proyecto nació en octubre de 2004 bajo la denominación Google Print. Así fue presentado en la Feria del Libro de Frankfurt, aunque después se llamara, definitivamente, Google Books.
Debo reconocerlo. La primera vez que oí hablar de este proyecto me maravilló. La idea nos acercaba al (¿mito?) del conocimiento universal. En internet hay una ingente cantidad de información, especialmente sobre las dos últimas décadas, cuando en los países más avanzados empezó a generalizarse el acceso. Desde el año 2000, todo está exhaustivamente documentado en internet, pero no es tan fácil encontrar información anterior a 1990. El proyecto que anunciaban Larry Page y Sergey Brin allá por 2004 nos llevaba a plantearnos si sería posible que cada ordenador estuviera conectado por medio de internet a todo el conocimiento de la humanidad.
Albergar el conocimiento universal ha sido durante siglos una ilusión recurrente de soñadores e intelectuales. Por primera vez parecía estar realmente cerca, aunque se necesitarían varias décadas para llevarlo a cabo. Se trata de la ilusión de una moderna biblioteca de Alejandría, abierta y digital.
La biblioteca de Alejandría fue en su época la más grande del mundo. Impulsada por Ptolomeo I en el siglo III a. J.C., estaba ubicada en la ciudad egipcia de Alejandría y llegó a albergar 900 000 manuscritos. Su destrucción se atribuye, según la fuente que consultemos, a romanos, cristianos o musulmanes. Sin embargo, no se sabe con certeza lo que sucedió realmente. Era un paraíso del conocimiento y de la investigación, algo inigualable para científicos, profesores, filósofos y estudiosos de su tiempo, quienes por colaborar y trabajar en ella obtenían manutención gratuita en la ciudad, e incluso se veían eximidos de pagar impuestos. ¡Vamos, que ya en el siglo III a. J.C. tenían unas condiciones de trabajo similares a las de los modernos ingenieros de Google! Tal vez por ese motivo algunos de los grandes pensadores de la Antigüedad estudiaron o desarrollaron su actividad en Alejandría, entre ellos Arquímedes o Euricles.
En aquella época, la voracidad de Ptolomeo I hacía que se compraran miles de manuscritos de todas partes del mundo conocido, pero del mismo modo obligaba a que se confiscaran los papiros de los barcos que se acercaban a la ciudad. Estos documentos eran requisados y copiados. Después devolvían las copias a sus legítimos propietarios y el original quedaba almacenado en la biblioteca. Ya en la Antigüedad no se podía aspirar a construir un auténtico monopolio cultural sin pisotear algunos derechos fundamentales. Como veremos a continuación, los tiempos no han cambiado demasiado pese a los años transcurridos. Google también ha necesitado con frecuencia pisotear algunos derechos fundamentales para poner en marcha su sueño.
Generalmente nada ni nadie se eleva a la categoría de mito sin pasar por el cementerio o sin caer en desgracia. La biblioteca de Alejandría no podía ser una excepción. Su destrucción resulta controvertida. Suele atribuirse a un incendio ordenado por Julio César, quien por entonces perseguía a Pompeyo. A ese incendio sobreviviría una gran parte del material allí contenido. Siglos más tarde, tras diversas guerras e incendios, la colección como tal acabó destruida y saqueada. Ahí terminó el primer gran intento de acumular el conocimiento de la humanidad. Hasta que, dos mil años después, llegó Google.
Larry y Sergey nos planteaban algo que iba mucho más allá de un servicio convencional. Se trataba de la auténtica revolución del conocimiento. A primera vista parecía apasionante, pero con el paso de los meses iban apareciendo nubarrones sobre lo que era una bella idea, tal vez utópica.
La base de datos de Google Books estaba en continuo y rápido crecimiento. En marzo de 2007 tenía digitalizado un millón de libros. En 2010 anunciaban haber escaneado 15 millones de los 130 millones de libros que estimaban que habría en el mundo en ese momento. Estamos hablando de algo más del 10% del conocimiento impreso del planeta escaneado página a página, organizado y almacenado en menos de una década.
Nadie puede negar a nuestros románticos jóvenes que son temerarios y, sobre todo, innovadores. Cuenta Richard. L. Brant en su libro Las dos caras de Google (Editorial Viceversa, 2010) que ya en 2002 Larry Page decidió averiguar el tiempo necesario para escanear un libro de 300 páginas. Acompañado por la entonces jefa de Producto de Google, Marissa Mayer, se encerró en su despacho con una cámara de fotos y un cronometro. Larry hacía fotografías mientras Marissa pasaba las páginas. Así comprobaron que el tiempo estimado era de 40 minutos, lo que representaba su primer hándicap: escanear millones de obras debería ser un trabajo mucho más rápido. Si querían lograr algún día su objetivo, deberían innovar e idear una manera mucho más eficiente, y a su vez respetuosa con los originales, para poder hacerlo.
Y lo consiguieron. Larry formó un equipo de trabajo y visitaron proyectos de digitalización por todo el mundo. Unió al equipo a expertos en robótica que pudieran diseñar una máquina para pasar las páginas y escanear a gran velocidad sin dañar los ejemplares. Los ingenieros de Google crearon un software de reconocimiento de caracteres que detectara hasta los más extraños e inusuales tipos y tamaños de texto. Aparentemente, lo consiguieron. Años más tarde, cuando la rectora de la Universidad de Michigan, Mary Sue Coleman, le confesó a Larry Page que los archivos de la universidad, que consistían en siete millones de libros, podían escanearse en un período de tiempo no inferior a mil años, este, sin inmutarse, le replicó que Google podría hacerlo en seis.
Nadie sabe a cierta ciencia qué hardware emplean para el proyecto Google Books. Se especula que escanean a una velocidad de mil páginas por minuto con cámaras Ephel 323. Resulta curioso no saber a ciencia cierta cómo funciona un proyecto cuya finalidad es, precisamente, poner a nuestra disposición conocimiento. Como ya has visto en otras ocasiones, Google tiene mucho interés en devorar y apropiarse de la información, pero no tanto en que los demás conozcamos la suya propia, que suele estar protegida por rigurosos acuerdos de confidencialidad.
Muchos analistas, especialmente los europeos, fueron enfriando la cálida acogida al proyecto allá por 2004. Aparecían enormes lagunas legales y, sorprendentemente, la empresa no mostraba interés en el campo de la protección de los derechos de autor. Google había cerrado acuerdos para digitalizar los archivos bibliográficos de algunas bibliotecas y universidades, pero no se había interesado en llegar a ningún tipo de acuerdo con los propietarios de los derechos. Es más, la empresa de Page y Brin actuaba como si no los necesitara, lo que resultaba tremendamente inquietante.
Entiendo que tal vez, llegados a este punto, mi inquietud pueda no ser compartida. El malvado autor de estas líneas no está sino preocupándose de sí mismo. ¿Tal vez por su almuerzo? Es decir, ¿por los derechos de sus propias obras? A lo mejor en este momento alguien podría ver en mí una actitud provinciana en la que prevalece mi interés personal sobre el sueño del conocimiento global. Puedo garantizar que no hay nada más lejos de la realidad.
¿Será entonces que soy un malvado que intenta tirar abajo la brillante idea de estos chicos, agarrándome al clavo ardiendo de los argumentos de sociedades de derechos de autor que a todos nos caen mal? En absoluto. De entrada, y aunque eso pueda hacer perder un poco de halo de glamour al proyecto, es importante destacar que no fue Google el primero en tener esta ambiciosa idea, que ha sido recurrente en los últimos años. Si hoy tenemos en mente el proyecto de Google Books, y no algunos otros, es sobre todo porque los de Mountain View son una inmensa máquina de comunicación que lo engulle todo a su paso haciéndolo suyo. Son magníficos en la ejecución, son innovadores, pero sobre todo destacan por ser expertos en marketing. Aunque no lo pueda parecer, ideas como la de crear una enorme biblioteca universal no les pertenecen.
Corría el año… ¡1971! cuando Michael Hart impulsó el denominado Proyecto Gutenberg. Se trataba de un plan para difundir gratuitamente por medios digitales el mayor número posible de obras libres de derechos. Esta fue la primera biblioteca digital colaborativa. Aunque el proyecto data de los años setenta, despegó significativamente con la llegada de internet en los noventa. Centenares de voluntarios procedentes de todas las partes del mundo escanean, corrigen y escriben cuando así lo requiere la antigüedad de las obras. En la actualidad, el proyecto es accesible desde la dirección web http://www.gutenberg.org, y se muestra en varios idiomas. Ofrece 20 000 libros en descarga directa y otros 100 000 desde páginas asociadas. No es el único proyecto, pero sí el más antiguo, con la intención de digitalizar el contenido bibliográfico universal.
El propio gigante del comercio electrónico Amazon.com escanea las primeras páginas de las obras que vende para ofrecer una visión inicial a los futuros compradores. En la actualidad tiene 35 millones de obras escaneadas en su web bajo el epígrafe Search inside the book (función que permite consultar un número limitado de páginas de un libro).
¿Por qué estando ya en marcha Google no se suma a alguno de estos proyectos? Porque el objetivo no es crear la gran biblioteca. ¡El objetivo es que sea sólo suya!
Las entidades gestoras de derechos de autor son, desde la llegada de internet, los malos de la película. En los años noventa la Business Software Alliance, impulsada entre otros por Microsoft y Adobe, era literalmente el enemigo público número uno de los internautas —bueno, tal vez el número dos, tras el propio Microsoft—. En España, la Sociedad General de Autores y Editores es la organización con peor imagen pública del país, por delante de Hacienda. Al gran público poco le importa qué pasa con estas organizaciones, e incluso resulta simpático que alguien pueda atropellar sus derechos. Así, no es raro encontrar argumentos contrarios a los derechos de autor en internet tan sólo porque perjudican a estas organizaciones. No dejan de ser el «pim pam pum» de la época de las puntocom. Nadie sufre si les sacuden, e incluso resulta socorrido y ciertamente populista hacerlo de vez en cuando. Pero al margen del daño a este tipo de organizaciones, y a miles, tal vez millones de autores, me preocupan varias cosas más de este proyecto. En primer lugar, ¿por qué Google? El hecho de escanear, archivar, conservar y difundir todo el conocimiento de la humanidad, ¿no representa algo de un valor cultural e intelectual tan serio que no debería estar en manos de una única empresa privada? ¿Tiene sentido que esta información sea tutelada por alguien que, además, es experto en la explotación publicitaria de contenidos y que goza de un monopolio en internet? Si el proyecto sigue adelante y dentro de una década Google Books es, tal vez, el mayor archivo editorial de la historia, es decir, la biblioteca de Alejandría 2.0, ¿quién nos garantiza que si Google dejara de existir —árboles más grandes han caído— este enorme legado cultural seguiría siendo accesible?
Y, finalmente, ¿en qué condiciones legales? ¿Qué ocurre si dentro de algunos años Google quiere cambiar, como dueño de la base de datos, las normas de utilización? ¿Por qué motivo nos tendríamos que plegar a las normas e imposiciones de una empresa privada para acceder a un contenido que, de facto, no es suyo, y que está formado por obras de nuestro patrimonio histórico y cultural?
Son muchos los interrogantes, pero eso no impidió que en una primera fase se suscribieran acuerdos con las universidades de Harvard, Stanford, Oxford, Michigan y la Biblioteca Pública de Nueva York. El entusiasmo de algunas de estas instituciones con el proyecto resulta curioso. Me gustaría destacar el cambio histórico que supone ver a una empresa estadounidense, que en aquel momento contaba con tan sólo seis años de vida, firmando un acuerdo que imponía sus condiciones a instituciones como la prestigiosa Universidad de Harvard, con 375 años a sus espaldas, y en posesión de una de las bibliotecas más prestigiosas del mundo que, fundada en 1638, cuenta con un catálogo de más de quince millones de ejemplares.
Todas estas bibliotecas poseen millones de ejemplares que pueden ser consultados por estudiantes e investigadores. Pero ¿eso les daba derecho a cedérselos a una empresa privada para ser copiados? Y algo más curioso todavía. Si ya resulta dudoso el derecho de copia de esos archivos, colgarlos en internet o explotarlos publicitariamente en el futuro, ¿no es ir mucho más allá de los límites razonables? El proyecto era ambicioso, aunque sobre él planeaban enormes nubarrones legales que, por increíble que parezca, habían sido subestimados por la empresa. El acuerdo con esos primeros socios establecía que Google correría con el costo de la digitalización y que cedería una copia de las obras a las instituciones, de manera que cada una de ellas tendría derecho, sin costo alguno, a una copia digital de sus propios archivos —no del total— que podría utilizar libremente, siempre y cuando fuera sin ánimo de lucro. En otras palabras, Google y las instituciones serían cotitulares de cada fichero, pero sólo desde Googleplex podrían utilizarlos en su conjunto y lucrarse de esta inmensa fuente de conocimiento. ¡No es un trato filantrópico, precisamente!
A lo largo de los años otras instituciones fueron suscribiendo el acuerdo, como las universidades de Princeton, Texas, California, e incluso algunas instituciones europeas, como la Biblioteca Municipal de Lyon, en Francia, la Biblioteca de Babaria, en Alemania, o la Universidad Complutense de Madrid. En España siempre hemos sido fácilmente colonizados. Cuando nuevos vientos traen novedosos productos desde el otro lado del Atlántico, es habitual que nos hagamos sus principales embajadores y los asumamos como si fueran propios, enterrando con ello las alternativas patrias. Tal vez por ello no resulta extraño que la participación de la Universidad Complutense de Madrid sea entusiasta, y que presuma con orgullo de ser el primer colaborador no anglosajón del proyecto. No sé si esto debería ser motivo de especial orgullo. La Universidad Complutense de Madrid, que dispone de interesantes bibliotecas y archivos, explica en su página web cómo se realizarán dos copias. La de Google, que por el hecho de haber realizado la digitalización puede disponer de la suya como considere, y la de la propia universidad, que podrá utilizarse «siempre y cuando sea sin ánimo de lucro». Sorprende que tu propio archivo sea tutelado por un tercero y que este, además, te otorgue una licencia que indica cómo y cuándo puedes hacer uso de él. Es evidente que lo que les interesa es que no puedas ganar dinero con ello, ya que para esa parte —pensarán Larry y Sergey— ¡ya están ellos!
En la Universidad Complutense se escanearán 110 000 libros, artículos y manuscritos con el ánimo de preservarlos para el futuro y apoyar la función docente. Según indican, lo harán con el máximo respeto a los derechos de propiedad intelectual, por lo que las obras que, según la legislación española, son dudosas de estar protegidas, no son escaneadas.
Como antes comenté, todos estos acuerdos se rodean de un curioso secretismo. Cuando uno quiere rascar un poco y pregunta, siempre se topa con una puerta infranqueable. «Hemos firmado un acuerdo de confidencialidad, por lo que no puedo oficialmente explicarte más…» Los acuerdos de confidencialidad no son precisamente un estándar en el mundo docente y entre los bibliotecarios. Es más, son insólitos, les inquietan y molestan, lo que entiendo perfectamente. Sin embargo, Google considera que se trata de compromisos comerciales. Sus equipos y tecnología son estratégicos, y no deben ser revelados en ningún caso. No sólo firman acuerdos de confidencialidad con las universidades o bibliotecas. Incluso llegan a firmarlos individualmente todas las personas con participación directa en el proyecto.
Todo eso resulta curioso. Soy de los que piensan que si no quieres que un acuerdo sea revelado no debes darle importancia. De ese modo nunca debes firmar un acuerdo de confidencialidad o, como dicen los anglosajones, non-disclosure agreement (NDA).
Una vez que propones la firma y la llevas a cabo, es una situación tan extraordinaria para los firmantes que ya tienen algo que comentar en petit comité que, a buen seguro, resultará un buen colofón a una cena de amigos. No falla. Me cuentan que la situación llegó a ser tan surrealista en el entorno de una de las universidades que la extrema interpretación de estos contratos hacía que no pudieran explicar a sus propios compañeros qué sucedía en determinadas habitaciones, que quedaron totalmente restringidas. Resulta paradójico estar obligado a guardar secreto cuando el proyecto trata de universalizar el acceso a la información. Resulta difícil de explicar cómo puedes tener acceso al mundo, pero no a la habitación contigua. Una vez más, se trata de un ejemplo de doble rasero a la hora de querer facilitar la práctica totalidad de la información —la mía, ¡no, gracias!
El dilema estaba servido. Google daba por descontado que habría polémica por sus métodos e intenciones. Suponían que podría desencadenarse una intensa batalla judicial. Tanto es así que en los acuerdos firmados con las instituciones se dejaba claro que la empresa correría con todos los costos legales de la iniciativa, en previsión de lo que podría llegar a ser una auténtica lluvia de demandas por parte no sólo de autores y editores, sino también de ilustradores y fotógrafos que podrían ver reproducidas, y accesibles desde internet, sus obras sin consentimiento alguno.
Google no suele empezar con la ardua tarea comercial de firmar acuerdos con titulares de derechos. Más bien ocurre todo lo contrario. En una curiosa interpretación de la ley, considera que puede utilizar todos los contenidos que le plazca y que, si algún tercero quiere eliminarlos, debe dirigirse a Google para solicitarlo. Si no lo hace, está autorizando su uso de facto.
Hace algunos años, junto a varios socios, cofundé Yes.fm, una empresa de internet que, a modo de radio online, pretendía ofrecer música a la carta bajo demanda. Recuerdo que el equipo de Yes.fm tardó más de un año de intensas gestiones, viajes y reuniones en Madrid, Londres, París o Nueva York para obtener el beneplácito de la industria y así distribuir su contenido.
En aquel entonces se contaban con los dedos de una mano las empresas que habían suscrito acuerdos con las cuatro grandes discográficas, conocidas como las majors[33], para ofrecer su catálogo editorial. Recuerdo esos meses como frustrantes por la lentitud de las negociaciones y por la enorme cantidad de dinero, tiempo, recursos en relaciones públicas y viajes invertidos. Finalmente lo conseguimos, y no sólo pudimos contar con el contenido de las majors, sino que además lanzamos el producto con acuerdos con otros sellos discográficos independientes como BOA, Blanco y Negro, The Orchard, Popstock o Subterfuge. En cierto modo, nuestro sueño era poder ofrecer nuestra propia biblioteca de Alejandría, en este caso musical, ofreciendo un acceso al mayor catálogo imaginable. Pues bien, todo ese esfuerzo económico y humano fue un absurdo innecesario, simplemente una pérdida de tiempo según The Google Way of Life. Si quisiéramos haber actuado como Google en los inicios de su proyecto editorial, deberíamos haber acudido a una tienda, haber llegado a un acuerdo para grabar toda su música y haberla distribuido hasta que algún editor se quejara y, en ese caso, siguiendo la lógica de Mountain View, nuestra responsabilidad se limitaría a eliminar de nuestro catálogo sus canciones o a negociar con él. La diferencia entre Google y nosotros era que si hubiéramos actuado así, hoy en día, a buen seguro, habríamos pasado por la cárcel tras multitud de demandas de la industria musical al completo. Una compañía como la suya se puede permitir interpretaciones creativas y ventajosas de la ley y pisar ciertos jardines sin que el jardinero los persiga guadaña en la mano, sino más bien interesado en llegar a un acuerdo económico para cobrar la próxima vez que pases por su jardín. Eso hace que a determinadas empresas, que se llenan la boca presumiendo de innovación, les resulte más fácil desarrollar determinados productos, ya que no a todo el mundo le cuesta lo mismo cruzar las líneas rojas trazadas por la ley, o el sentido común.
Por eso este proyecto sólo podría haber nacido desde Google. En cualquier otra multinacional tecnológica no hubiera pasado de ser una idea formulada e inmediatamente desechada por las consecuencias legales que podría acarrear. Sin embargo, en Google tienen una vasta experiencia en «tirar para adelante» e ir arreglando esos detalles a posteriori. Así lo hicieron con las patentes iniciales de Adwords, o con los problemas de propiedad intelectual de Google News, o del mismo YouTube. El mundo va rápido. Seamos los primeros, comámonos el mercado y después haremos lo que haya que hacer, llegando a acuerdos comerciales si es necesario. Y lo hacen. Pero siempre tras haber engullido el segmento y destruido cualquier atisbo de competencia. Amén.
Así fue. Como estaba previsto, o al menos se intuía, empezaron los problemas, y Google intentó llegar a acuerdos y subsanarlos, bajo amenaza de verse inmerso en batallas judiciales paralelas a una intensa labor de digitalización de millones de obras. En 2005 llegaron las primeras demandas en Estados Unidos por parte del Gremio de Autores de América, y de la Asociación de Editores de Estados Unidos. Ambas, por separado, denunciaron a Google por «infracción masiva de los derechos de autor de sus asociados». Los editores sostienen que, aunque Google no muestra más que una parte de los libros sujetos a derechos de autor —no así los libros huérfanos o de dominio público, que ofrece íntegramente—, no tiene derechos de copia y almacenaje de las obras, y mucho menos para la posterior redistribución de las mismas.
En 2008, Google cerró un acuerdo extrajudicial con la industria editorial norteamericana a través del cual se comprometía a pagar la cantidad de 125 millones de dólares por todas las obras que había ido escaneando a cambio de la retirada de las demandas y de poder seguir ofreciendo íntegramente las obras huérfanas, o sin derechos de autor. Además, se comprometía a correr con todos los costos judiciales de los demandantes, a pagarles el 63% de los ingresos del sitio —publicidad, suscripciones, ventas online—, y a crear un registro, denominado Books Right Registry, para intentar localizar a los creadores o titulares de derechos de autor de obras antiguas, dándoles de este modo la posibilidad de retirar sus obras del proyecto si así lo deseaban.
En una declaración posterior, Eric Schmidt se refirió a este acuerdo como un guiño de Google en señal de confianza a la industria, ya que, en virtud de su interpretación legal, la compañía insistía —tal vez como aviso a otras entidades de derechos— en considerar que no debe ni necesita llegar a ningún acuerdo de distribución con los autores. A pesar de todo, este acuerdo no gustó demasiado, ni a las autoridades de la competencia ni a la Open Book Alliance, una coalición que incluye a representantes de las bibliotecas, los periodistas y grandes empresas de la red —Microsoft, Amazon y Yahoo!—. Según afirmaban, «el acuerdo concederá a Google un monopolio sobre la digitalización de libros, incluidos los agotados o los que son de dominio público».
En 2011, el juez Denny Chin aceptó ese argumento e invalidó el acuerdo entre Google y la industria editorial estadounidense, ya que estimó que «no es equitativo, adecuado o razonable», y que otorgaría a Google una ventaja significativa sobre sus competidores «afianzando la posición dominante de las búsquedas online» de que dispone. La sentencia razona que «si bien la creación de una biblioteca digital universal beneficiaría a muchos, se estaría concediendo a Google derechos para explotar libros sin el permiso de los propietarios del copyright. De hecho, otorgaría a Google una ventaja significativa sobre sus competidores, gratificante para participar en la copia masiva de obras protegidas sin permiso, quedando liberado de las reclamaciones más allá de las que se presentan en el caso». En definitiva, la propuesta de acuerdo entre Google y los editores estadounidenses quedaba denegada. Aquello representó el mayor revés judicial para Google Books.
La empresa dijo que recurriría la sentencia y se defendió de las críticas al afirmar que su digitalización editorial online era un acto altruista «para proteger el patrimonio cultural del mundo» —pero ¡qué amables!—. Uno de sus fundadores, Sergey Brin, llegó a afirmar: «La famosa biblioteca de Alejandría fue quemada tres veces, al igual que la Biblioteca del Congreso de Estados Unidos. Espero que esta destrucción no vuelva a suceder. Si eso sucede, allí estará Google Books». ¡Y tú y yo pensábamos que querían apropiarse del contenido en exclusiva para explotarlo publicitariamente, y lo que realmente querían era ayudar a su conservación! ¡Qué malpensados somos!
Como en otras ocasiones, Google intenta convencernos de que darles una posición dominante en un mercado que les pone en disposición de rentabilizar todo el contenido del mundo, y de ser los dueños legales de la mayor base de datos de la historia, es un hecho altruista. Vamos, que lo hacen por nosotros, por nuestro bien, y que el interés de la compañía es casi meramente colateral. Entonces ¿por qué no lo hacen renunciando a la titularidad y exclusividad de la base de datos? Ya que es una iniciativa propia de una ONG, ¿por qué no renuncian a su explotación publicitaria y ceden sus derechos al mundo?
Fuera de Estados Unidos el proyecto recibió decenas de denuncias y de quejas. Una de las más destacadas llegó en 2006 por parte de una editorial francesa, La Martiniére, por digitalizar libros protegidos por derechos de autor. Estos libros no deberían estar disponibles en la red. El buscador se había comprometido a, en esos casos, sólo ofrecer pequeños fragmentos de las obras, generalmente en torno al 20% de su contenido, como resultado de las búsquedas. En 2009 la editorial ganó el juicio a Google Francia y recibió la cantidad de 300 000 euros en concepto de indemnización por daños y perjuicios. Del mismo modo, se condenó a Google a pagar 10 000 euros diarios por cada día que la empresa mantuviera en su base de datos ese contenido, al quedar probado para el tribunal «que Google violó claramente las leyes de derechos de autor al poner a disposición de los usuarios obras protegidas sin autorización de sus titulares». El Syndicat National de l’Edition en Francia, que se unió posteriormente a la demanda, dijo que Google había escaneado sin permiso unas 100 000 obras francesas protegidas por derechos de autor.
Finalmente, en agosto de 2011, La Martiniére y Google llegaron a un acuerdo que contemplará las obras descatalogadas de la firma gala que ya no están disponibles para la venta, pero que aún están sujetas a derechos de autor. Las compañías explicaron que la iniciativa tiene como objetivo dar «nueva vida» a las obras que se encuentran agotadas y descatalogadas para beneficio de los lectores —que pueden volver a descubrirlas—, de los autores —cuyas obras podrán volver a ser leídas—, y de los editores —que podrán beneficiarse de nuevas oportunidades de negocio.
En 2011, Francia continúa su lucha contra Google Books. Las editoriales francesas Gallimard, Flammarion y Albin Michel han demandado a Google por piratería argumentando que sus libros se escanearon sin su consentimiento, por lo que violaron la ley de copyright y esa práctica se considera literalmente «piratería informática». Como indemnización las editoriales pidieron 9,8 millones de euros, cifra a la que se llega al estimar mil euros por libro digitalizado sin autorización, unos 9797 y que van en aumento, ya que Google Books no ha parado de escanearlos.
Al más puro estilo francés, cuyo aprecio y defensa por la cultura es indiscutible, se plantearon la iniciativa de crear una biblioteca virtual para poder competir con Google, ya que veían no sólo una amenaza a la competencia en internet y a los derechos de autores y editores, sino un cierto afán imperialista por parte de Estados Unidos de acabar monopolizando la cultura. Podían llegar a ser dueños del mayor registro cultural del mundo y, por lo tanto, seleccionar qué obras deberían aparecer y cómo habían de hacerlo. El gran agitador de las conciencias francesas fue el prestigioso historiador francés Jean-Noël Jeanneney, director de la Biblioteca Nacional de Francia. Entre 2004 y 2006 invitó a Europa mediante diversos artículos de su libro Quand Google défie l’Europe (Mille et une nuits, 2006), y en diferentes intervenciones en la radio, a movilizarse y defenderse de lo que consideraba que podría ser un intento estadounidense, por medio de Google, de acaparar y monopolizar la cultura europea, alertando a los franceses de que, si no se reaccionaba de manera colectiva desde Europa, en unas décadas tal vez se estudiaría la Revolución francesa por medio de libros escritos en Estados Unidos. La sociedad cultural francesa se movilizó ante tal amenaza, y así nació, entre otros, el proyecto Gallica de manos de la Biblioteca Nacional Francesa.
El prestigio de Jean-Noël Jeanneney está fuera de toda duda. Se trata de uno de los intelectuales franceses clave en el presente siglo, y de los más firmes defensores de las letras galas. Pero, para ser justos, me gustaría matizar su entusiasta actitud europeísta. Por supuesto, se trata de una opinión muy personal, y entiendo que tal vez no la compartas. En primer lugar, nadie es independiente. Todos, incluido el propio Jean-Noël Jeanneney, tenemos intereses y nos vemos sujetos a presiones e influencias. Sí, desde luego, también yo. A fin de cuentas, de nadie hay que estar más protegido que de los imparciales, porque son los que están sobornados por las dos partes.
El caso es que cada vez que en Francia alguien enarbola la bandera europea con fuerza para defenderse de otro más grande que viene de fuera, siempre se me dibuja una sonrisa en la boca y no puedo evitar pensar que lo que quiere defender no es una posición europea, sino la suya propia, la francesa, y para ello necesita manos amigas. Para defender su propia despensa necesita «peones», y resulta relativamente fácil buscar un punto común de defensa, simpatías y adhesiones en el viejo continente ante un enemigo común: los temibles estadounidenses.
En la actualidad, Google continúa trabajando y escaneando, pero ha ido llegando, obligado por las circunstancias, a acuerdos con editoriales en los que ofrece promoción de las obras en Google Books y en el buscador a cambio de poder escanearlas y almacenarlas en su base de datos, mostrando sólo parte del contenido. Del mismo modo, los ingresos publicitarios que se generen en las páginas de contenidos se reparten con la empresa titular de los derechos.
El interés en el proyecto por parte de Google continúa intacto, aunque habrá que ver si resuelven los problemas judiciales en Estados Unidos. Por lo pronto, la compañía ha anunciado en julio de 2011 su primer lector de eBooks en colaboración con el fabricante iRives. El dispositivo no sólo será compatible con Google Books, sino que estará totalmente integrado. Se denominará iRives Story HD y costará 139 dólares en su lanzamiento. Se trata, sin duda, de un experimento de Google para poder competir con el Kindle de Amazon.com. Es decir, la manera de Google de buscarse más enemigos.
Como ya he comentado, en 2006 Google adquirió YouTube.com, el portal de publicación de vídeos gratuitos más popular y utilizado en internet, por la sorprendente cantidad en esa fecha de 1650 millones de dólares. En aquel entonces YouTube contaba tan sólo con 29 meses de vida, y Google, con una ingente cantidad de dinero en sus arcas, no pudo resistirse a la adquisición de la web que gestionaba el 46% del mercado de publicación de vídeos en internet.
Con sede en San Bruno (California), la empresa fue creada en 2005 por tres jóvenes ex empleados de PayPal: Steve Chen, Jawed Karim y Chad Hurley. El primer vídeo se publicó el 23 de abril de 2005, y francamente no tenía mucho glamour. Se trataba de uno de los fundadores del sitio web, Karim, paseando por el zoo de San Diego. Pese a ese espantoso vídeo inicial, el fondo de capital de riesgo Sequoia acabó invirtiendo en el proyecto 11,5 millones de dólares. En 2006 servían ya más de cien millones de vídeos al día, y tenían 29 millones de usuarios únicos, frente a los apenas siete que alcanzaba a tener su competencia, Google Video.
Horas antes de la adquisición, tanto Google como YouTube habían anunciado acuerdos, por separado, con distintas compañías discográficas para eliminar obstáculos legales que pudiesen frenar la operación. El portal es en la actualidad —ya lo era entonces— el servicio líder de almacenamiento de vídeos en internet, pero tenía enormes problemas de gestión de derechos de propiedad intelectual. Para comprender la magnitud del éxito, uno de los más fulgurantes del mundo junto al propio Google o Facebook, pensemos que en 2011 se subían cada minuto del día unas 24 horas de archivos de vídeo a YouTube. Es un portal de tremenda penetración social y un interesante soporte publicitario. De hecho, en 2008 se decía que un anuncio en su página principal podría costar 175 000 dólares diarios, con la obligación además de pagar otros 50 000 dólares más en otros servicios de Google.
Los problemas de YouTube han sido una constante y han dado bastantes quebraderos de cabeza a Google. Tanto es así que se han realizado grandes inversiones para tratar de calmar a la industria audiovisual en el espinoso asunto de los derechos de propiedad intelectual. Los problemas legales llegaban a amenazar la viabilidad del modelo de negocio, así como la continuidad del proyecto.
YouTube.com no es un portal web más. Podría llegar a ser el embrión de la primera estación de televisión global multi-idioma, además del mayor videoclub del mundo, para lo que ya se hacen pruebas en Estados Unidos. Todo eso, y muchas cosas más, pueden ser lucrativos modelos de negocio para Google en el futuro. Además, no hay que despreciar el espaldarazo que YouTube da a su buscador. ¿Qué mejor respaldo para Google.com que disponer del dominio de la mayor parte del contenido audiovisual en internet? O, dicho de otro modo, de los más de mil millones de vídeos que hay en YouTube, ¿quién los busca, almacena y nos da justo los vídeos que necesitamos? Evidentemente, ellos, para decepción de sus rivales, que se sienten impotentes al intentar competir.
El hecho de dar un espaldarazo a tu buscador cuando ya dominas el mercado no es una razón de suficiente peso para invertir más de 1600 millones de dólares. El tráfico actual de YouTube es una razón de por sí mucho más convincente. Recuerdo que en 2006, cuando se anunció por sorpresa la compra de YouTube, algunos analistas creían que al triunvirato compuesto por Larry, Sergey y Eric les habían engañado, y que habían pagado una cantidad de dinero desorbitada por algo que no lo valía. Cuando se produjo aquella operación, un socio mío me envío por email el vídeo grabado pocas horas antes en el que dos de los jovencísimos fundadores de YouTube, Chad Hurley y Steve Chen, hacían una grabación casera delante de un restaurante de la cadena Fridays, en Estados Unidos, explicando a los usuarios del portal la venta a Google —que, por otro lado, no tenía mucha más explicación que: «¡Nos hemos forrado! ¿Cómo no vamos a vender?»—. En el vídeo apenas balbuceaban, entre ataques de risa, las razones de la venta, que denominaban «unión de los reyes de la búsqueda y del vídeo». Durante los últimos segundos, ante la risa nerviosa de ambos, descubrí qué cara se te queda cuando ganas en menos de dos años más de mil millones de dólares. Recomiendo ver ese vídeo[34] porque es divertido y te hace pensar un instante cómo podrías reaccionar ante algo así. De lo que puedo dar fe es que yo elegiría otro tipo de restaurante para una celebración de ese calibre.
En la actualidad se estima que el portal sigue perdiendo importantes cantidades de dinero cada año. Sin embargo, ya nadie piensa que aquella cifra fuera una locura, sobre todo si se analizan sus datos y se comprueba cómo se ha consolidado en internet. Aunque Google no ofrece datos financieros sobre YouTube —¡qué novedad!— diferentes analistas calculan pérdidas de entre los 470 millones de dólares anuales que estimaba Credit Suisse, a los 200 millones que en 2008 calculaba la revista Forbes.
Al margen de los resultados financieros, el resto de sus números son espectaculares. Valga como muestra un botón: en 2007, YouTube.com consumía más ancho de banda que todo internet conjuntamente en 2000. En mayo de 2010 servían dos mil millones de vídeos al día. Un año más tarde, en mayo de 2011, habían crecido «un poco más» y el portal servía tres mil millones de vídeos diarios.
El crecimiento y popularidad de los vídeos de YouTube se ha sostenido en torno a la explotación de contenidos de terceros sin autorización, lo que ha levantado decenas de miles de peticiones de retirada de vídeos, así como cientos de problemas judiciales. Cabe mencionar que la empresa ha realizado algunos esfuerzos en los últimos años para llegar a acuerdos de explotación, y que ha puesto en marcha herramientas para el control de los derechos.
En 2007 se vieron obligados a presentar una herramienta denominada Content ID con la que intentaron proteger el contenido sujeto a derechos de autor. Los productores, artistas, cadenas de televisión, etc., entregaban previamente copias de sus audios y vídeos, que eran analizados por un software específico que los almacenaba en una base de datos. Cada vídeo que se subía a YouTube se comparaba con estos archivos guardados. La compañía indicaba que comparaban tanto audio como vídeo, e incluso personas. Si se detectaba un contenido que estaba protegido por Content ID, el titular de los derechos podía ejercer varias acciones, entre ellas bloquearlo y eliminarlo, dejarlo o monetizarlo, ganando así parte de los beneficios que ese vídeo generara con la publicidad que lo acompañaba.
En 2010 se había reclamado la titularidad de más de ¡cien millones de vídeos protegidos! por medio de la herramienta Content ID. En ese momento YouTube tenía en su haber una base de datos con más de 300 000 horas de contenido susceptible de protección. Se trata, posiblemente, de la mayor fuente audiovisual de este tipo en el mundo.
Esta herramienta, que adolece de algunos problemas conceptuales de los que luego hablaré, ha supuesto una inversión de más de diez millones de dólares y un gran argumento legal frente a jueces de todo el mundo, ya que permite argüir que se hacen esfuerzos para limitar el uso indebido de contenidos al desarrollar herramientas que minimizan lo que es un hecho: la constante vulneración de los derechos de autor, de la que se lucra —todo hay que decirlo— la propia empresa.
En 2011 se filtró que los vídeos protegidos suponían un tercio de los ingresos publicitarios del portal, en lo que sin duda era parte de un reclamo publicitario de la empresa. Pretendían con ello lanzar un mensaje del tipo: «Estamos repartiendo una parte sugerente del pastel, licéncianos tu contenido, únete a la fiesta y gana dinero con nosotros».
Durante los últimos años, cada vez que un usuario subía un vídeo a YouTube recibía un mensaje que le pedía: «Por favor, no suba vídeos protegidos por derechos de autor, como vídeos musicales y series de televisión». Salvando las distancias, eso es lo mismo que poner un cartel en una sucursal bancaria con la siguiente invitación: «Por favor, no nos atraquen». La efectividad es equiparable. Sin duda alguna, la persona que intente subir un vídeo con derechos —o atracar el banco— no se va a amedrentar por la simpática nota disuasoria. Igual, eso sí, hasta le provoca una sonrisa y le alegra el día.
El sistema es maquiavélico. Si tú, querido googlefan, entras en internet, abres YouTube.com y subes el último vídeo musical de Justin Bieber, además de tener un dudoso gusto musical estás entrando en un surrealista juego en el que tú no ganas nada, y las visitas —entiendo que la mayoría de enamoradizas quinceañeras— llegarán por cientos o miles a ver el vídeo en cuestión. Mientras tanto, Google se frota las manos y lanza anuncios como loco. Si semanas más tarde llegara un email de la discográfica Island Records, que posee los derechos del cantante, Google, que ha estado ingresando dinero con el tráfico generado, se lavará las manos, retirará el vídeo y enviará un email de disculpas alegando que lo desconocían y que ha sido obra de un malvado usuario. Explicarán además que han actuado en consecuencia y, para no ser demasiado duros contigo, te obligarán a ver un vídeo educativo —en YouTube, por supuesto— que explica cómo funcionan los derechos de autor, así como cuál debería ser tu comportamiento cívico para estar en el lado de «los buenos».
Y así es como sucede. Te envían a ver un vídeo de dibujos animados, ¡tal vez esperando que así lo entiendas mejor! —vamos, como si fuera para tontos— basado en una conocida serie web de dibujos titulada Happy Three Friends[35]. El vídeo no es que haga furor, precisamente. Las opiniones de los propios usuarios no dejan lugar a dudas. En agosto de 2011 indicaban lo siguiente: «Me gusta: 1863. No me gusta: 9724».
Déjame destacar un mensaje curioso del vídeo, que dice, literalmente: «[…] puedes enfrentarte a una demanda, perder tu botín y tu cuenta de YouTube». Al margen de lo ridículo que puede resultar ver unos dibujos animados dándonos lecciones morales y amenazándonos… ¿¡Perder tu botín!? Si soy yo quien sube a YouTube algún contenido inapropiado no gano nada con ello, ¡ningún botín! El botín, si por ello entendemos el dinero generado irregularmente, lo ingresa siempre YouTube, incluso aunque haya que retirar el vídeo. Parece evidente que luego no llaman a los anunciantes, a los que ha cobrado por aparecer en esas páginas, para devolvérselo. ¡Ahora resulta que el Capitán Pirata nos da lecciones morales desde su escondite sentado sobre el tesoro robado!
En conclusión, unos simpáticos animalitos nos explican qué son y cómo funcionan los derechos de autor. Nos dicen que no seamos malvados y que no subamos contenido protegido a YouTube, ya que ellos ganarán mucho dinero, y eso no estaría del todo bien. Al terminar te hacen un examen por medio de un formulario para ver si, pobre ignorante, entendiste las bonitas enseñanzas de los dibujitos y si, en definitiva, comprendes la diferencia que existe entre lo que es y lo que no es tuyo. Según el resultado que obtengas en esas preguntas, te dejan retomar tu cuenta. Son cuatro preguntas y, por supuesto, de lo más sesudo, como, por ejemplo:
—Si creas contenido nuevo ciento por ciento original, podrás protegerte de reclamaciones por infracción de derechos de copyright. ¿Verdadero o falso?
Aun así, desde luego hay gente que no acierta la respuesta correcta. De hecho creo que, dentro de mi particular sentido del humor, tiene una cierta gracia hacerlo. Pues bien, este mecanismo de «reinserción social» para los violadores de derechos de autor, es decir, lo del vídeo para niños pequeños y las cuatro preguntitas finales, se llama pretenciosamente Google Copyright School, en un intento de dar armas a los asesores legales de la compañía para argumentar que hasta educan a los que no cumplen, y que además les explican cómo hacerlo. En otras palabras, lejos de permitir y fomentar la piratería, incluso cumplen con una función educativa y social. ¡Todo un detalle por su parte tras ocho años lucrándose con ello!
El caso es que si incumples reiteradamente —al menos tres veces— las políticas de derechos de autor, tienen derecho a determinar que es un caso grave y que eres muy malo. Si eso ocurre, pueden cerrar tu cuenta en YouTube, con el enorme disgusto que eso te causaría, ya que te obligarían a abrir otra, posiblemente también en YouTube, unos minutos más tarde. Ya lo dice el refrán. ¡A grandes males, grandes remedios!
De todas formas, existen decenas de tutoriales en internet que explican cómo puedes saltarte la herramienta Content ID de manera sencilla y en pocos pasos, y subir todo tipo de vídeos sin ser detectado para evitar que tengas que acudir —a tu edad— a la escuela de copyright, y con ello tener que ver ese espantoso vídeo de ciervos y gatitos. No hay que ir muy lejos. Esos tutoriales, que explican cómo saltarse las normas, no están escondidos en lo más recóndito y oscuro de la red. Están todos en YouTube.com bajo títulos tan sugerentes como «saltarse el copyright de YouTube». Los tienes de todo tipo y en todos los idiomas, como a ellos les gusta: a tan sólo a un clic de distancia. Curioso, ¿verdad?
En el caso de otros servicios he criticado que Google ha basado parte de su éxito en tomar todo lo que ha querido con el objeto de dominar el mercado para después, cuando han llegado las quejas y las denuncias, gozar de las ventajas de una ilegítima posición dominante. En el caso de YouTube podemos decir casi lo mismo, con la salvedad de que la labor no la iniciaron ellos, aunque después no les ha importado lo más mínimo continuarla. Copiar de un sitio es plagio, de dos documentación. YouTube es la empresa más documentada del mundo.
Content ID es una buena herramienta. A pesar de ello, como decía antes, adolece de algunos problemas conceptuales. Para evitar ser expoliada, una empresa generadora de contenido debe, en primer lugar, entregar a Google su patrimonio, es decir, todo su contenido. Esto es duro y especialmente sangrante. Es como tener que entregar a Barbarroja el tesoro para que garantice nuestra inmunidad. El zorro se compromete a cuidar del gallinero y repartir sus ingresos. Para muchas empresas es un escenario duro de afrontar. En segundo lugar, deben ser de nuevo las empresas las que muevan ficha y las que eviten que se vulneren sus derechos. ¿Es eso lógico?
Seamos serios. El éxito de este enorme archivo multimedia no está basado en los vídeos generados por los usuarios —tipo «vacaciones en la playa»—, sino que se ha cimentado sobre los vídeos musicales, escenas de películas o series de televisión que están generalmente sujetos a derechos de autor. Es cierto que hay algunos casos extraordinarios que se convierten en vídeos virales y dan la vuelta al mundo, bien porque son divertidos o porque tienen algo excepcional. Así, por ejemplo, uno de los más famosos es Charlie bit my finger, un vídeo de 2007 en el que un niño de unos cuatro años es mordido por Charlie, su hermano pequeño, en el dedo. A simple vista no parece tener demasiado atractivo. Simplemente es simpático y divertido si tienes un par de minutos libres, aunque sólo sea por ver las caras de los niños —por cierto, ¡maldito sea el padre que permitía encantado los mordiscos mientras grababa, y que ahora explota el fenómeno!—. Pues bien, este vídeo tenía en agosto de 2011 más de 370 millones de visualizaciones, de las que posiblemente, si así lo solicitó el orgulloso padre del niño mordido, está ganando dinero debido al reparto de publicidad con YouTube sobre los clics en la publicidad del vídeo. Todo lo cual convertirá este mordisco en el más rentable de la historia, tanto por sus beneficios como por su difusión. Los padres, el niño mordedor y el mordido incluso acudieron a explicar el fenómeno a varias televisiones en Estados Unidos, en alguna de las cuales, de forma delirante, se llegó a animar al menor a morder a su hermano en directo.
Es un vídeo tan inocente como viral. Tal vez esa sea la razón del patético intento de los padres de las criaturas de alargar el fenómeno con otros mordiscos grabados en vídeo a lo largo de los años, con títulos tan elaborados como Charlie bit my finger, again. Como todo esto sólo podría suceder en Estados Unidos, es posible que dentro de unos años, al cumplir su mayoría de edad, el agredido infante demande a sus progenitores por daños y perjuicios, así como por las taras psicológicas que, a buen seguro, le han quedado para el resto de su vida.
Al margen de casos excepcionales como este, el éxito se ha basado en el otro tipo de contenido —musical, televisivo y cinematográfico—, que generalmente se mostraba sin ningún permiso ni autorización. Cuando YouTube fue líder absoluto del mercado de los vídeos, y las alternativas, como Vimeo o Metacafe, estaban a años luz de distancia, Google empezó a regular el problema intentando poner en marcha acuerdos con los grandes gestores de contenidos de la industria.
A día de hoy los problemas continúan, aunque en menor medida. Creo sinceramente que la labor de control del contenido —que intentan cumplir por una vez— es difícil y digna de elogio, aunque, a su vez, es una clara muestra de que Google no se cree sus propios argumentos legales basados, como hemos visto, en una interpretación creativa del DMCA[36] de Estados Unidos. En otras palabras, si sus tesis fueran ciertas y pudieran albergar cualquier tipo de contenido, retirándolo sólo en caso de recibir alguna reclamación, no hubiera sido necesario desarrollar herramientas, cancelar cuentas o «educar» a los malvados usuarios, ¿no te parece? La respuesta es obvia. Google sabía que necesitaría argumentos de más peso si no quería que le lloviesen demandas en cada rincón del planeta.
Uno de los conflictos más sonados comenzó en 2007, cuando Viacom interpuso una demanda millonaria contra YouTube. La empresa es dueña, entre otras, de la cadena de televisión MTV y de la productora cinematográfica Paramount Pictures. Los demandantes informaron que aspiraban a recibir más de mil millones de dólares en concepto de daños y perjuicios por «violación masiva e internacional de los derechos de autor». Además, intentaron hacerse con un mandato judicial que previera otras «violaciones» futuras. Según los demandantes, había al menos 160 000 vídeos de su programación sin autorización con los que Google se estaba lucrando, ya que habían sido vistos más de 1500 millones de veces. Lo cierto es que tras este enorme problema legal con Viacom, todavía en curso, la empresa se apresuró a firmar acuerdos con medios de comunicación y compañías discográficas y cinematográficas, como la BBC, CBS y NBC Universal.
En esta batalla, que aún dura, YouTube acusó, en un sorprendente giro de los acontecimientos, a Viacom por incurrir en prácticas engañosas, dado que mientras interponía dicha demanda para que retirara el material con copyright subía en secreto vídeos de su propiedad a YouTube para que se promocionaran sus contenidos. Estas prácticas se hicieron públicas por el asesor legal de la empresa, que mostraba cómo enviaban a sus empleados a subir vídeos desde páginas que no podían rastrearse, con lo que se rozaba el espionaje industrial. Google ponía de manifiesto que poseía documentos de origen interno de Viacom que les habían sido filtrados.
Finalmente, en junio de 2010 la justicia estadounidense falló a favor de YouTube y dictaminó que cumple con el Digital Millenium Copyright Act (DMCA), dado que coopera con los autores para proteger sus derechos por medio de herramientas ad hoc del servicio, así como mediante la retirada del contenido tras las quejas por las infracciones. Siempre vi muy curiosa esta interpretación de los derechos de autor. Me da la sensación de que la estrategia legal emprendida por Viacom no estaba tan bien enfocada y cometieron más errores en su planteamiento legal. Es evidente que si ha habido un uso indebido, una reproducción ilícita y un lucro por parte de Google, debería haber una indemnización. Sea como fuere, el único país del mundo donde los derechos de autor tienen ese limbo, que permite sacar a tu ejército de abogados hacia una interpretación tan creativa de los derechos de terceros, es Estados Unidos. En Europa la compañía no podría agarrarse a argumentos tan peregrinos para lucrarse con el contenido que no les pertenece. Aun así, Viacom ha recurrido la sentencia y el tema aún no está del todo cerrado.
No es el primer caso, ni será el último, de violación masiva de los derechos de autor por parte de YouTube, pero tiene una particularidad. Generalmente hay un punto de inflexión en el que las empresas que han demandado a Google, y que son generadoras de contenidos, llegan a acuerdos. Suelen retirar las demandas si hay una indemnización, y se sigue adelante, sin rencores, compartiendo los ingresos. Esto aún no ha ocurrido en este caso. En mi opinión, si Viacom sigue peleando tarde o temprano terminará por llegar a un acuerdo.
Jeremy Zweig, vicepresidente de Comunicaciones Corporativas de Viacom, me comentaba que «los instrumentos para identificar y eliminar contenido donde se hayan podido vulnerar los derechos de autor han estado disponibles durante años. Tenían acceso a las herramientas de filtrado, pero sólo las quieren utilizar para beneficio de las empresas y los artistas con los que habían formalizado un contrato, y no con nosotros. Así que este es uno de nuestros argumentos —sí, sabían que era piratería, y tenían las herramientas para su control, pero sólo nos las habrían ofrecido en caso de llegar a un acuerdo comercial con ellos—. No creemos que sea una forma muy legal de actuar».
Google se ha defendido siempre apoyándose en dos argumentos. El primero, que ellos no pueden ejercer una censura previa de los contenidos que suben los usuarios. El segundo, que no son quienes deban revisar todo el contenido almacenado en YouTube; debe ser responsabilidad del titular de los derechos la tarea de investigar, informar y señalar los contenidos que, a su juicio, deben ser retirados.
Esto último nos lleva a un delirante escenario en el que Google nos estaría ayudando a reducir la falta de empleo en la industria cultural. O al menos en las compañías que no quieran o no estén interesadas en firmar acuerdos de distribución con ellos, ya que si quieren salvaguardar sus derechos, y que sus contenidos no se reproduzcan sin su autorización generando beneficios para quien no ha participado en modo alguno en su elaboración, deberían contratar a decenas de investigadores especializados en YouTube.com para encontrarlos. Podríamos incluso ponerle un cargo más rimbombante, como «YouTube detective manager». Serían precisos departamentos enteros para patrullar día y noche por la inmensa web de vídeos buscando, identificando y finalmente denunciando cualquier irregularidad que encontraran. Es decir, para que no aparezcan en mi casa las joyas de tu abuela, paga de tu bolsillo a un policía que revise quién entra y quién sale de mis instalaciones. Sorprendente.
En España existe una situación similar, en este caso con el Grupo Mediaset, propietario de Telecinco, que interpuso una demanda contra YouTube. Según afirmó la propia cadena, considera que el portal de vídeos actúa como un pirata industrial al difundir ilícitamente, sin autorización, los contenidos de Telecinco, explotándolos comercialmente a espaldas del titular de los derechos. Paolo Vasile, consejero delegado de Telecinco, declaraba que antes se «identificaba al pirata por el top manta», y que ahora «han llegado piratas nuevos a los que, además, se celebra». A diferencia de los primeros, «no son inmigrantes clandestinos. ¡Estos cotizan en Bolsa!». La respuesta de los portavoces fue desvincularse de cualquier problema inculpando indirectamente a sus usuarios. «Nosotros sólo somos meros intermediarios. Además, cualquier cadena de televisión puede notificarnos, cuando exista un vídeo de su propiedad en nuestro portal, si consideran que se vulnera su derecho a la propiedad intelectual. Son los usuarios quienes suben los archivos, y no podemos quitarlos uno a uno. Por ese motivo, hemos puesto a disposición de las cadenas de televisión un programa gratuito con el que pueden proteger sus contenidos, evitando así que puedan ser reproducidos».
Mario Rodríguez Valderas, director general corporativo de Telecinco, con quien mantuve una entrevista, hacía hincapié de manera muy acertada en lo siguiente: «Efectivamente, el usuario sube los vídeos, pero el beneficio siempre lo obtienen los mismos. YouTube obtiene beneficios sobre la base del trabajo de otros. Los vídeos que son propiedad de nuestra cadena no tienen por qué estar expuestos en otro sitio que el de la propia cadena, ni generar rendimientos económicos para terceros».
Esta situación me retrotrae a cuando me dedicaba, hace casi veinte años, al sector de la hostelería. Recuerdo que abrí mi segunda discoteca en Madrid en el barrio de Salamanca con un conocido y acaudalado empresario del sector, que tenía además otras salas. Siempre me sorprendió su poder adquisitivo y su calidad de vida. En España, generalmente, la hostelería da para vivir bastante bien, pero no tanto como lo que yo veía en él, y eso me intrigaba. Meses después llegué a la conclusión de que sus ingentes beneficios eran colaterales al negocio, y que posiblemente los recibía de la venta de todo tipo de sustancias ilegales en sus locales, ya que su personal parecía «no ver» determinadas actitudes dependiendo de quién las llevara a cabo. Él, por supuesto, no cometía ningún delito, pero siempre pensé que se lucraba y que, al menos, su dejadez en el control facilitaba dichas actividades. Si la policía venía una noche a revisar el local y realizaba algún cacheo o detención, él permanecía impasible. No era su problema, él no había hecho nada. ¿No te parece algo similar a la manera en la que Google gestiona los derechos de autor?
Es la tenue línea que separa la moralidad de la legalidad. Puede haber algún piratilla que pisa la línea constantemente, y que juega con ello. Conozco a algunos que asumen ese riesgo en el negocio de la tecnología, y llegan al límite. Pero a una de las mayores empresas del mundo, que genera ingresos de casi 30 000 millones de dólares al año, y que con el Don’t be evil por bandera habla de ganar dinero de forma ética y respetable, ¿no se le debería exigir más en el terreno de lo moral? ¿No deberían ser, cuando menos, más escrupulosos con determinadas actitudes?
En el caso de Telecinco, tras dos años de litigio, el tribunal sentenció en septiembre de 2010 que «YouTube es un intermediario y que compete a quien cuelgue el material la responsabilidad de infringir o no los derechos de la propiedad intelectual, y a las terceras partes en reclamar esa protección. YouTube no tiene que aplicar una censura previa antes de su publicación». Para mi sorpresa, Google ganó el caso en primera instancia, y por ello Telecinco ha recurrido la sentencia. Según Mario Rodríguez Valderas, pese a la derrota inicial, la expectativa del recurso es muy positiva, ya que «el tribunal vio indicios de delito, y por ello prohibieron a YouTube reproducir nuestros vídeos. Pero al tribunal le ha venido muy grande condenar a YouTube por las repercusiones que tendría… Sería sentar un precedente, y tal vez deba hacerlo un tribunal de más alto rango».
En todo este juego de demandas y presiones hay una doble moral que no puedo obviar. Telecinco también emite en su programación vídeos de YouTube en programas de zapping, humor o similares. Aunque Google no es el titular de esos vídeos, su utilización hace que este sea un caso de doble moral. Están condenados a entenderse, y lo acabarán haciendo. Telecinco intentará conseguir una indemnización, alcanzar un acuerdo y negociar desde la posición más ventajosa posible.
Yo apuesto a que eso sucederá. A día de hoy, el director general corporativo de Telecinco me lo negaba rotundamente: «Tal y como se desarrollan los hechos, son ellos quienes deben dar el primer paso, y no lo están haciendo. Además, tarde o temprano cederán. Las cosas tienen que cambiar sí o sí, es cuestión de tiempo, y sé que vamos a ganar esta batalla». Apuesto a que acabaremos algún día gritando como en un combate de boxeo amañado: «¡Que se besen, que se besen!». Tiempo al tiempo.